
Veri Mühendisleri İçin 3 Önemli Araç
Büyük Veri Danışmanı Anton Bondar; Apache Hadoop, Apache Spark ve Apache Airflow hakkında bilgi veriyor!
Veri miktarı on gigabaytı aşarsa eğer data pipeline işlemek, depolamak ve yönetmek için özel teknolojiler kullanma zamanı gelmiş demektir. Bir veri mühendisinin temel becerisi, bu teknolojilerin bilgisidir. Cognizant'ta Büyük Veri Danışmanı ve Veri Mühendisliği kursu eğitmeni Anton Bondar, bir veri mühendisinin üç ana aracı hakkında verdiği bilgiler bu makalede sizleri bekliyor!
Kullanılan teknolojilerin bilinmemesi aşağıdakilere yol açabilir:
- Gerekli SLA'nın (hizmet düzeyi sözleşmesi) yerine getirilmemesi: Veri mühendisleri için son tarihler belirlidir. Verilerin hızlı işlenmesi, dahili ve harici kullanıcılara sağlanması gerekir. Bu, gerçek zamanlı analitiğin önemli bir unsur olduğu durumlarda daha da kıymetlidir.
- Altyapı maliyetlerinin artması: Veri Mühendisliği buluta doğru ilerler. Şirket içi BigData altyapısını kullanma ve bakım yapma maliyeti oldukça yüksek olduğundan ve artık küçük şirketler bile büyük miktarda veriyi işleyebildiğinden dolayı bulut sağlayıcıları “Kullandıkça Öde” (Pay-as-you-Go) faturalandırma modelinin kullanımına geçtiler. Yalnızca kullandığınız kaynaklar için ödeme yaparsınız. Böyle bir durumda araçların verimsiz kullanımı, bilgi işlem kaynaklarının aşırı tüketilmesine yol açacaktır. Bu durum ise on binlerce dolarlık ek maliyetle sonuçlanacak demektir.
Apache Hadoop
2006 yılında ortaya çıkan bu teknoloji, çok büyük miktarda verinin saklanmasını, işlenmesini ve analiz edilmesini mümkün kıldı. Modern anlamda büyük veri yani Big Data bu teknoloji ile başlamıştır.
Apache Hadoop bu yüzlerce ve binlerce sunucudan oluşan kümeler üzerinde dağıtılmış programları yürütmek için bir dizi kitaplık ve bir çerçevedir. (Framework). Hadoop, görevi küme düğümleri arasında dağıtılan ve aynı alt görevlere bölen bir programlama modeli olan Google MapReduce'tan esinlenmiştir.
Data Lake'in tarihi Apache Hadoop ile başlar. Hadoop, bilgi işlem gücünün kullanımını demokratikleştirmiş, bunun sonucunda ise daha fazla şirket büyük miktarda veriyi analiz edip bunlar üzerinde sorgu yazabilmiş ve bilgi işlem güçlerini yatay olarak ölçeklendirebilmiştir.
Hadoop Common'a (diğer Hadoop modüllerinin çalışmasını destekleyen bir dizi hizmet, kitaplık ve yardımcı program) ek olarak, Apache Hadoop üç modülden oluşur:
- HDFS (bir kümede dağıtılmış veri depolamada kullanılır)
- MapReduce (veri işleme motorudur)
- YARN (küme kaynak yönetimi ve görev zamanlaması için kullanılır)
Veri Mühendisi çoğunlukla HDFS ve MapReduce ile çalışır.
HDFS(Hadoop Distributed File System)
Dışarıdan, HDFS herhangi bir diğer POSIX dosya sistemine benzer, dosya ve dizinlerin listesini görebilir, kullanıcılara belirli klasörleri kullanma izni verebilir ve diğerlerinin kullanımını kısıtlayabilir. Hadoop kümesine/kümesinden dosya yükleyebiliriz. İlk bakışta, HDFS'nin yetenekleri etkileyici değildir ancak burada verilerin "gizli donanımın altında" tam olarak nasıl depolandığı önemlidir çünkü Data Lake yaklaşımına ivme kazandıran HDFS olmuştur ve yine de Data Lake on-premises şirket içinde uygulamanın birkaç yolundan biri olmaya devam edecektir.
Hadi Apache Hadoop mimarisinin neye benzediğini hatırlayalım;
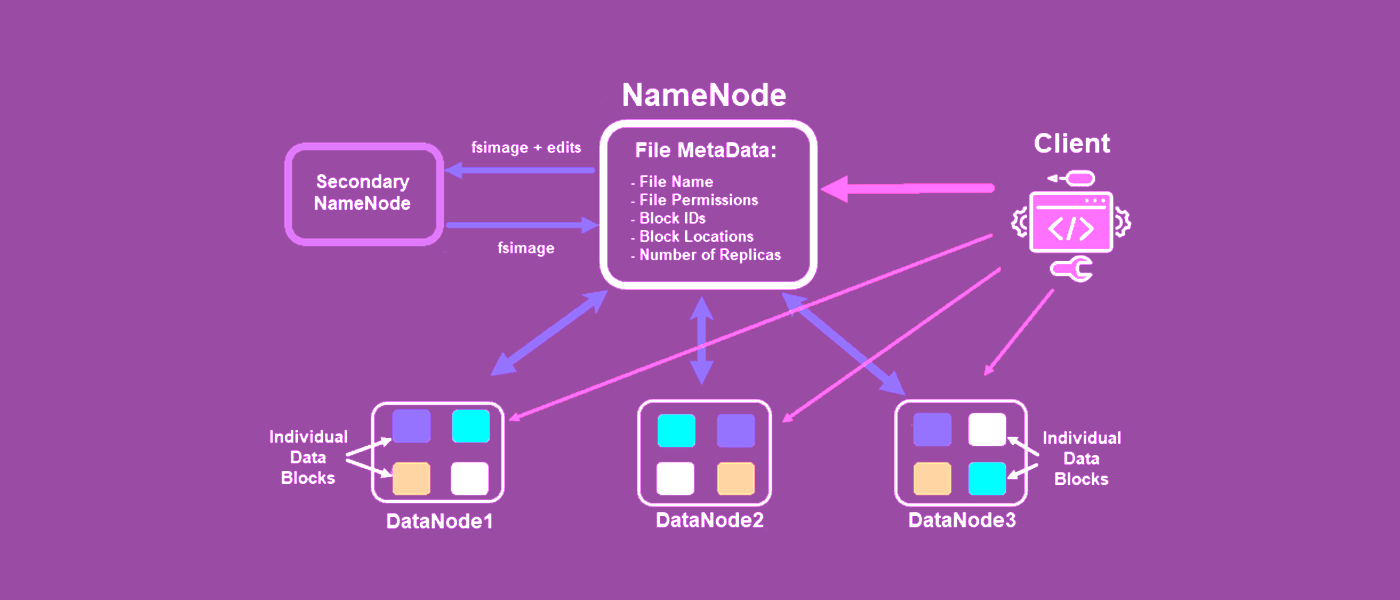
HDFS'deki veriler/dosyalar, veri düğümlerinde depolanır, ancak saf formlarında değildir. Bir kullanıcı/program Hadoop'a bir dosya yüklediğinde, dosyayı ad düğümüne gönderir (Hadoop kümesi ile dış dünya arasındaki tüm iletişim, ad düğümü aracılığıyla gerçekleşir). Gelen dosyayı birkaç bloğa böler ve farklı veri düğümlerine gönderir. Aynı dosyanın blokları zorunlu olarak farklı veri düğümlerinde ve sonuç olarak Hadoop kümesinin farklı sunucularında bulunmalıdır. Dosya her bloktan sonra iki kez kopyalanır ve orijinal bloğun bu iki kopyası diğer herhangi iki veri düğümüne kopyalanır.

Peki bunun nedeni nedir?
Resimde gösterildiği gibi girdi dosyası 4 bloğa bölünmüş ve her blok iki kez kopyalanmıştır.
Bir hatta iki veri düğümü düşerse, dosya yine de kullanılabilir durumda kalacaktır. Yüklü büyük bir kümedeki tek sunucuların düşmesi yaygın bir durumdur.
Diğer bir önemli artı, dosyanın farklı bloklarını aynı anda birkaç Hadoop küme sunucusundan indirerek, HDFS'den büyük bir dosyayı sırayla değil paralel olarak yükleyebilmemizdir. Böylece, dosya bloklarının bulunduğu veri düğümlerinin sayısına katkı veren bir boşaltma ivmesi verir.


Bu yaklaşım ise neredeyse sınırsız yatay ölçeklendirmeye izin verir.
Data Lake'te alan mı tükeniyor? Kümeye yeni bir sunucu ekleyin ve ona bir veri düğümü atayın.
MapReduce
Büyük veri kümelerinin paralel şekilde işlenmesi için bir işleme motorudur. Nasıl çalıştığına bir örnek verelim.
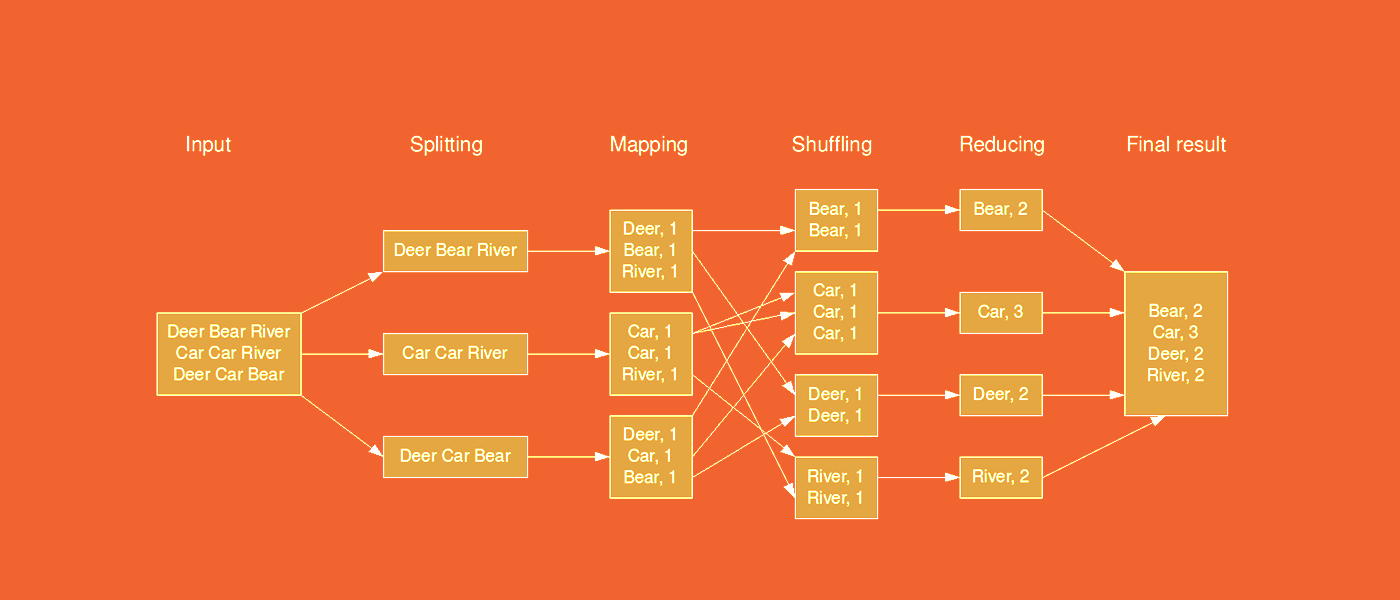
MapReduce “kelime sayma işlemi”
Girdi dosyası, Hadoop'a yüklediğimiz .txt biçiminde bir metindir ve şimdi bloklara bölünmüş olarak HDFS'de bulunmaktadır. Görevimiz, benzersiz kelimelerin bir listesini derleyerek ve bu metinde her birinin kaç kez geçtiğini belirleyerek dosyayı analiz etmektir.
İlk olarak, haritalama işlemi gerçekleştirilir. Hadoop MapReduce blokları alır ve her kelimeye “1” değerini atar. Sonuç, anahtarın bir kelime olduğu ve liste içinde benzersiz olmadığı, değerin bir olduğu, anahtar/değer biçiminde bir listedir.
Bundan sonra, karıştırma (shuffling) gerçekleşir. Veri Düğümü, işlemin sonunda aynı anahtarların yan yana olması için anahtar-değer çiftlerini değiş tokuş etmeye başlar. Bundan hemen sonra azaltma yani reducing işlemi başlar: Aynı anahtarların değerleri toplanır.
Çıktı, benzersiz kelimelerin listesini ve metindeki numaralarını içeren bir dosyadır.
Haritalama ve küçültme işlemleri, her bir veri düğümünde bloklar için ayrı ayrı gerçekleştirilir.
Word Count programı için Java kodu
MapReduce, veri işleme konusunda oldukça dayanıklı bir yaklaşımdır. Eğer MapReduce'un yürütülmesi sırasında kümenin (cluster) üçte biri çökerse, iş (job) gecikmeli de olsa başarıyla tamamlanır.
Hadoop MapReduce'un temel dezavantajı ise düşük verimliliğidir. Birçok teknoloji, MapReduce ile aynı işlemleri çok daha hızlı gerçekleştirebilir. Örneğin; Apache Spark, Apache Impala veya Apache Mahout gibi.
Hadoop'ta dağıtılmış veri işleme bu şekilde çalışır. Yeterli güç yok, işler yavaş çalışıyor ve kod mümkün olduğunca optimize edilmiş durumda mı? Hadoop kümesine yeni bir sunucu ekler ve onu Data Node'a atarız - böylece paralel olarak daha fazla Haritalama veya Küçültme işlemi gerçekleştirebiliriz.
Ayrıca MapReduce her türlü veri işlemini desteklemez. Yukarıdaki şekilde veri bloklarının birbirinden bağımsız olarak ayrıldığını ve işlendiğini görebilirsiniz. MapReduce ile elemanlar arasındaki ilişkiyi analiz etmek imkansızdır, sadece sıralı analitik işlemleri destekler.
Yine de, MapReduce'un önemli bir artısı var. Kural olarak, verileri işlemek istediğimizde, onu hesaplama gücüne getiriyoruz ancak Hadoop MapReduce ile bunun tersi doğrudur: veriler zaten bir Veri Gölü görevi gören HDFS'dedir. İlk Harita işlemi, veri bloklarıyla aynı Veri Düğümlerinde gerçekleştirilir.
Apache Spark
Bu, dağıtılmış bellek içi veri işleme için bir BigData çerçevesidir. Spark, hem yapılandırılmış verilerin (tablo biçiminde), yarı yapılandırılmış verilerin (json, yaml, xml vb.) hem de yapılandırılmamış verilerin (metinler ve diğer medya biçimleri) işlenmesini destekler.
Spark, Hadoop Ekosisteminin bir parçasıdır, ancak hem Hadoop kümesiyle etkileşim kurabilir, hem de HDFS'de veri alıp depolayabilir ve Hadoop ile aynı küme sunucularında çalışabilir veya Hadoop'tan bağımsız çalışabilir.
Apache Spark, dört programlama dili Python, Java, Scala, R için bir API'ye (Web API değil) sahiptir:
Spark öncelikle Scala'da yazıldığından, maksimum verimlilik için Scala ve (daha az ölçüde) Java kullanmak en iyisidir.
Ancak Spark Jobs yazılması için en popüler dil Python'dur. Kodu daha okunabilir ve bakımını daha kolay hale getiren Spark ile etkileşim için basit ve net bir API sağlar. Python ayrıca Scala veya Java'da bulunmayan birçok veri görselleştirme seçeneği ekler.
PySpark (Python'un Spark arabirimi), temel Spark SQL modülüyle birlikte kullanıldığında, size diğer tüm programlama dilleriyle aynı performansı verir. Apache Spark, verileri verimli bir şekilde işlemenizi sağlar. Örneğin yukarıda bahsettiğimiz WordCount programı, Hadoop MapReduce'tan 100 kat daha hızlı çalışıyor. Bu, dağıtılmış mimari ve bellek içi hesaplamalar sayesinde mümkündür.
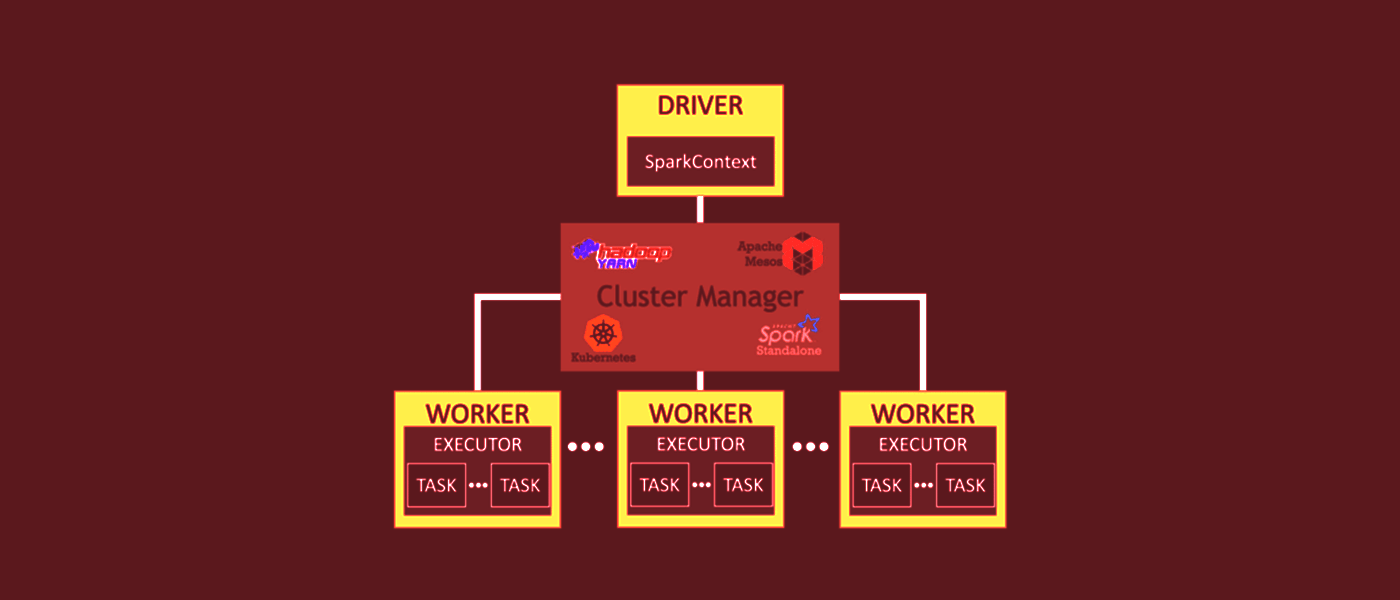
Spark'taki tüm hesaplamalar RAM'de gerçekleşir.
Spark, hem toplu hem de akış veri işleme yeteneğine sahiptir.
Apache Spark'ın dört bileşeni vardır:
- MLlib - makine öğrenimi görevleri için araç kitaplığı
- Akış - gerçek zamanlı analitik için araçlar
- Yapılandırılmış verilerle çalışmak için SQL modülü
- GraphX - grafik veri yapılarını işlemek için kütüphane
Apache Spark'ta veriler RDD (Resilient Distributed Dataset), DataFrame ve Dataset olarak temsil edilebilir.
RDD, Spark'taki ana veri yapısıdır, DataFrame'ler ve Veri Kümeleri, RDD'nin eklentileridir. Verilerinizi iyi biliyorsanız ve Spark'ın "iç organlarının" nasıl çalıştığını anlıyorsanız eğer bunlar önerilir. RDD'ler, yapılandırılmamış veriler (ortam veya metin gibi) üzerinde düşük düzeyli dönüşümler gerçekleştirmenize olanak tanır.
Dataframe, harici olarak Python Pandas Dataframes'e benzer ancak "gizli olarak" daha iyi bir optimizasyona sahiptir.
RDD'lerden farklı olarak DataFrame'deki veriler, tıpkı ilişkisel bir DBMS'de olduğu gibi sütunlar halinde düzenlenir. Dataframe, verilerin yapılandırılmasına yardımcı olur ve dağıtılmış verileri işlemek için uygun bir API sağlar.
Veri kümesi, Apache Spark'ta nispeten yeni bir veri temsili türüdür. RDD'nin avantajlarını Spark SQL optimizasyonlarıyla birleştirir. Veri Kümesi, Python ve R API'lerinde mevcut değildir ancak bazı özellikleri Dataframe'de mevcuttur.
Spark SQL, yapılandırılmış verilerle çalışmak için bir modüldür. Bunu bilmek bir zorunluluktur. RDD'den farklı olarak, işlenmekte olan verilerin yapısı ve veriler üzerinde gerçekleştirilen işlemler hakkında daha fazla bilgi veren yeni bir kavram olan DataFrame'i sunar. Spark'ın altında, bu bilgiler ek optimizasyon için kullanılır.
Spark SQL ile etkileşim kurmanın iki yolu vardır: SQL ve DataFrame API.

Aynı mantık, aynı performans, ancak farklı kod.
Apache Spark'ın bir başka özelliği de lazy evaluation kodda gizlidir. Spark kodu okuduğunda ve veri dönüşümlerini gördüğünüzde, bunları gerçekleştirmeye başlamaz. Bunları, veriler üzerinde gerçekleştirmek istediğiniz tüm işlemleri sırayla sakladığı bir DAG'ye yönlendirir. Bir "eylem" çağırdığınızda Spark, DAG'yi tüm işlemlerle birlikte analiz etmeye başlar, en uygun dönüşüm planını çizer ve bunları başlatır
Bir diğer önemli modül ise Spark Streaming. Akış verileriyle bile çalışmaz, micro-batches yani akıştan küçük veri parçalarını alır ve bunları tek tek işler. Her şeye rağmen Spark, kendisini Üretim Düzeyinde bir IoT çözümü olarak kabul ettirmiştir. Halihazırda DataFrame API'sini kullanıyorsanız “Yapılandırılmış Akış” kavramı, akış verileriyle ve statik verilerle aynı şekilde çalışmanıza olanak tanır.
Apache Airflow
Veri boru hatlarını (ETL süreçleri) geliştirmek, yönetmek ve izlemek için açık kaynaklı bir araçtır. İçindeki tüm mantık sadece Python kodu ile tanımlanır. Bunun ana avantajı, ETL görevlerini sürümlendirmek için Git'i kullanabilmenizdir. Airflow'daki ana konsept, Apache Spark ile aynı veri yapısı olan DAG'dir. Ancak burada DAG, katı bir sırayla takip eden adımlara bölünmüş ayrı bir ETL görevidir.
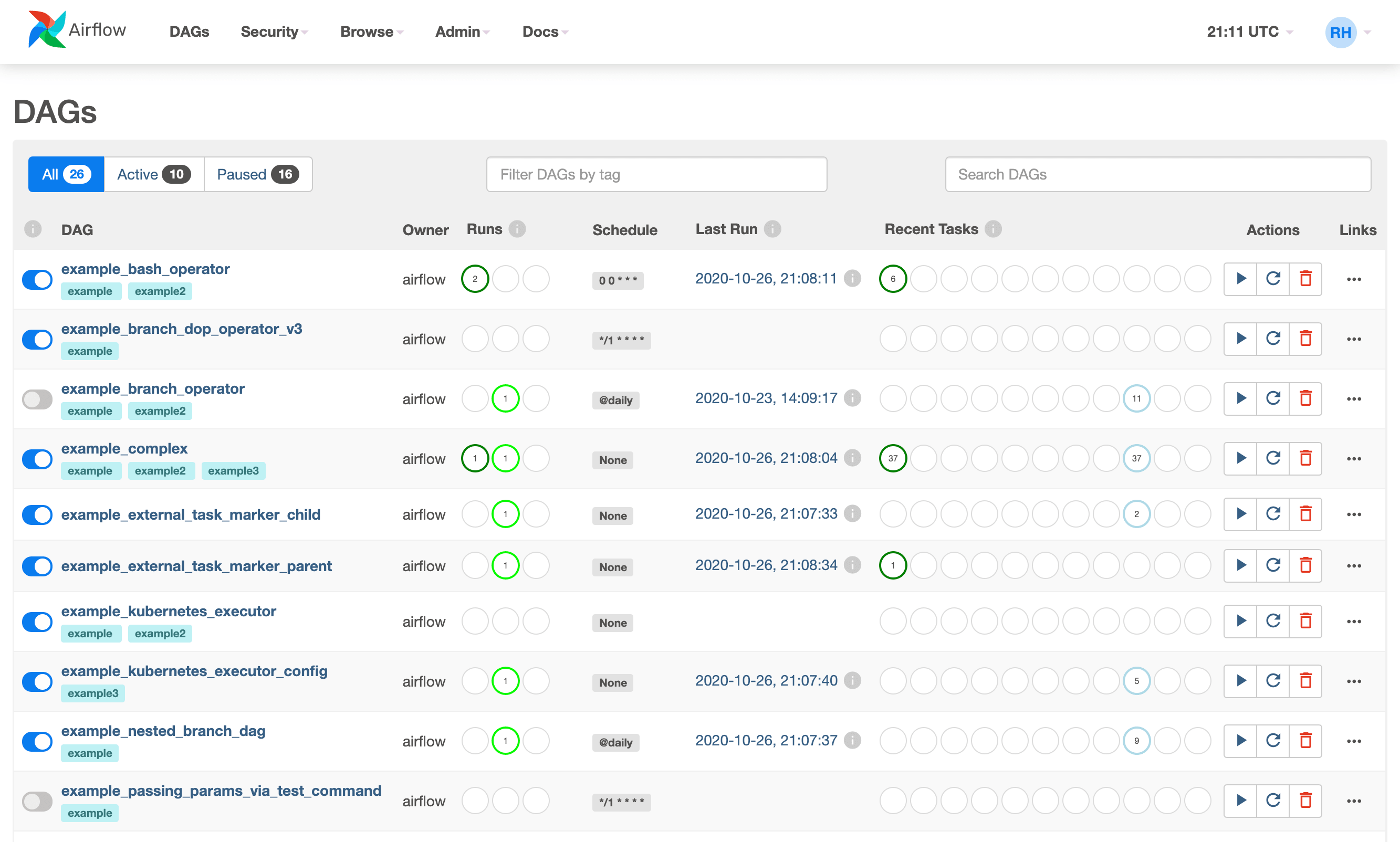
Tek bir DAG’ın arayüzü
DAG'deki her adım ayrı bir blokla gösterilir. Her adıma ek mantık atayabilir, adım bir hatayla sona ererse ne yapacağınızı söyleyebilir veya farklı durumlarda yürütme sırasını ayarlayabilirsiniz. Ayrıca, ayrıntılı yürütme günlükler, zamanı ve varsa hataların ayrıntılı bir açıklaması dahil olmak üzere her adımla ilgili ek bilgiler de bulabilirsiniz. Tüm bunlar, sıradan Python koduyla tanımlanır ve kesinlikle Pythonic görünür.
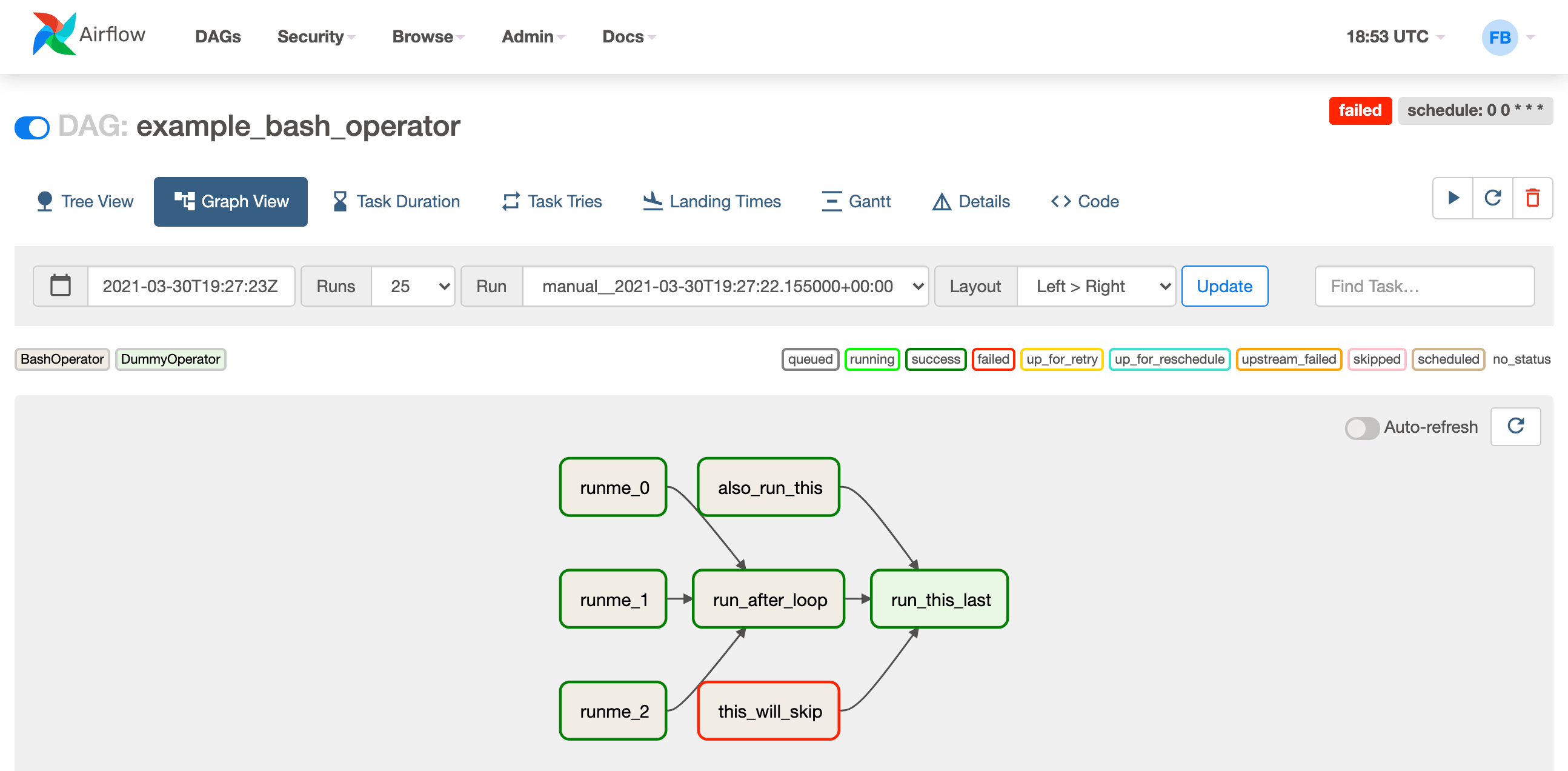
Airflow'un harici veri kaynaklarına dosyalar, DBMS, API bulut sağlayıcıları ve ayrıca harici veri işleme motorlarının çok sayıda bağlayıcısı vardır. Verilerle çalışmak için gerekli bir operatör veya motora bağlantı yoksa eğer Airflow işlevi kendi kendine yazılan modüllerle kolayca genişletilebilir. Airflow orijinal olarak yerleşik işlevleri ihtiyaçlarınıza göre değiştirebilmeniz için tasarlanmıştır. Apache Airflow size işlevsellik mirası ve kodun yeniden kullanımı şeklinde iyi mühendislik ilkelerini dayatıyor. Buna ek olarak, şifreler için yerleşik bir depolama, değişkenler ve meta verileri depolamak için bir NoSQL veritabanı dahil olmak üzere birçok ek araca sahiptir.


