
Word2Vec ile Eş Anlamlı Kelimeler Nasıl Bulunur?
Kelimeleri Vektörleştirmek İçin Kütüphaneler Neden Gereklidir?
Bilgisayarlar sadece sayılarla çalışabilir. Bir makinenin insan dilini kullanabilmesi için, tüm kelimelerin sayısal formata dönüştürülmesi gerekir. Bu işlem için, Word2Vec kelime gömme yöntemi kullanılabilir.

TrustYou'nun NLP Mühendisi Maria Obedkova ile birlikte Word2Vec'in nasıl çalıştığını anlayacağız.
Metinleri Sayılara Dönüştürme
Doğal Dil İşleme (NLP), metinleri sayılara dönüştürerek (vektörleştirerek) başlar. Metin parçalara, karakterlere, sözcüklere veya cümlelere bölünür ve ardından her parçaya sayısal bir değer atanır. Bir token için, birkaç sayıdan oluşan bir vektör atanabileceği gibi, bir sayı da atanabilir.
Word2Vec, Google'dan önceden eğitilmiş kelime vektör temsillerinden biridir.
Vektörler one-hot encoding ve embedding yaklaşımları kullanılarak oluşturulabilir. One-hot encoding'de, her vektör metindeki kelime sayısı kadar elemana sahiptir. Tokenin karşılığı hariç, vektörün tüm öğeleri 0'dır.
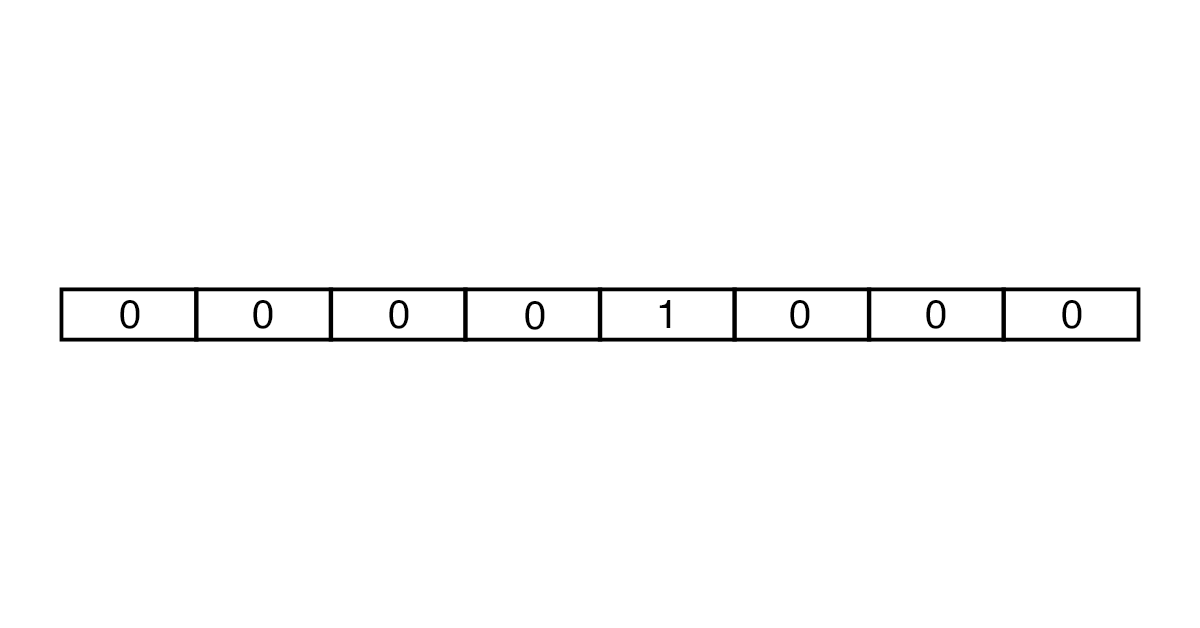
İlk olarak, analiz için kelime sayısı sınırlanır ve bunun için sözlükler kullanılır. Örneğin, İngilizce için Oxford 3000 ve Merriam-Webster sözlükleri kullanılmaktadır. Daha sonra, gerekli uzunlukta bir vektör oluşturmak için bir dizi sıfır ve bir birim kullanılır. Sonuç olarak, çok fazla bellek alanı kaplayan büyük vektörler elde edilir.


Embedding
Embedding, daha verimli ve daha az kaynak yoğun olarak kabul edilir. Bu durumda vektör sadece 0 ve 1'den değil, başka sayılardan da oluşabilir. Kelimeyi dönüştürmek için daha az "hücre" gerekebilir.
Vektörler, metnin bölümleri arasındaki farkı ve kalıpları gösterir.
Klasik bir örnek: "erkek" ve "kadın" kelimeleri arasındaki vektör, "amca" ve "teyze" kelimeleri arasındaki vektörle aynı olacaktır.
Vektörler arasındaki mesafeler kelimelerin anlamıyla eşdeğerdir. "Amca" - "erkek" + "kadın" ifadesi "teyzeye" yakın olacaktır, ancak bunun %100 karşılık gelmesi beklenemez.
Maria: "Word2Vec, büyük projeler için bir temel olarak ve araştırma alt görevlerini çözmenin bir yöntemi olarak kullanılıyor. Aynı zamanda, dağıtıcı anlambilimin (bir kelimenin bağlam tarafından tanımlanabilmesi) kendi eksiklikleri vardır. Örneğin, kelimelerin benzerliği her zaman anlamlarının aynı olduğunu göstermez."
Eş anlamlı arama: senaryo yazma
Word2Vec ile çalışmak için Gensim kütüphanesini kullanabilirsiniz. Bu kütüphane, doğal dil işleme ve belgelerden anlamsal temaların çıkarılmasına yardımcı olur. Gensim, metni bir vektöre dönüştürür ve vektörler arasındaki mesafeyi hesaplar. Bu kütüphanenin avantajı, tüm bilgileri belleğe yüklemeden, ancak diskten veri okumanıza izin vermesidir.
Aşağıda vektörlerin, arama sorgularının performansını artırmak için eş anlamlıları nasıl bulacağı bir örnek verelim.
- 1. Bilgi toplamak (parsing) ve sayfaları analiz etmek için kitaplıklar yükleyelim.pip install beautifulsoup4
pip install lxml - 2. Bir skript dosyası yazmaya başlayalım ve gerekli bağımlılıkları çıkaralım (ayrıştırma, normal görüntülerle çalışma, NLP ve Gensim).import bs4 as bs
import urllib.request import re import nltk from nltk.corpus import stopwords from gensim.models import Word2Vec - 3.Philip Dick'in ‘’ Do Androids Dream of Electric Sheep’’ adlı kitabınının ilgili Wikipedia sayfasını inceleyelim
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Do_Androids_Dream_of_Electric_Sheep') article = scrapped_data.read() - 4. BeautifulSoup nesnesini kullanarak paragraflardan metin çıkaralım.
parsed_article = bs.BeautifulSoup(article, 'lxml') paragraphs = parsed_article.find_all('p') - 5. Tüm metni article_text değişkeninde birleştirelim.
article_text = "" for p in paragraphs: article_text += p.text - 6. Herhangi bir skript dosyasının daha fazla çalışması, kaynak kodunu ne kadar iyi temizlediğinize bağlıdır. Bu nedenle, tüm karakterleri küçük harfe çevirmemiz gerekir.
cleaned_article = article_text.lower() - 7. Normal ifadeleri kullanarak yalnızca harfleri bırakır ve boşlukları kaldıralım.
cleaned_article = re.sub('[^a-z]', ' ', cleaned_article) cleaned_article = re.sub(r'\s+', ' ', cleaned_article) - 8. Veri seti eğitim için hazırlayalım.
all_sentences = nltk.sent_tokenize(cleaned_article) all_words = [nltk.word_tokenize(sent) for sent in all_sentences] - 9. Veri setini gözden geçirir ve durdurma kelimelerini kaldırırız (örneğin, anlam katmayanlar).
for i in range(len(all_words)): all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')] - 10. Metinde en sık bulunan kelimelerle bir Word2Vec modeli oluşturalım. Örneğin, en az 3 kez karşımıza çıkanlar (min_count=3).
word2vec = Word2Vec(all_words, min_count=3) - 11. Model çerçevesinde kitaba anlamca en yakın olan kelimeyi (topn=1) bulup çıkaralım.
print(word2vec.wv.most_similar('book', topn=1))
Sözlüğümüzde kitap kelimesinin en yakın eş anlamlısı - novel.
[('novel', 0.26558035612106323)]
Böylece, tek tek kelimelerin ve tüm sorguların yakın anlamlarını arayabilirsiniz.


