
İhtiyacınız olan 9 veri yapısı
Matris, dizi, yığın ve diğerleri.
Doksanlarda, Kore İleri Teknoloji Üniversitesi Profesörü Songchun Moon, Bill Gates'in girişimine Microsoft yerine Microdata adının verilmesini önerdi. Moon aynı zamanda verilerin ve yapının programlamanın geleceği olduğunu kaydetti.
Veri yapıları, bilgiyi depolama ve alma yollarıdır. Doğru yapı seçimi, görevi daha verimli bir şekilde gerçekleştirmeye yardımcı olacaktır. Yazılım geliştirmede veri yapıları önemlidir, algoritmaların çalışma şekli bunlara bağlıdır.
Bu makalede en sık kullanılan veri yapılarından bahsedeceğiz.
#1. Masif (dizi) (Array)
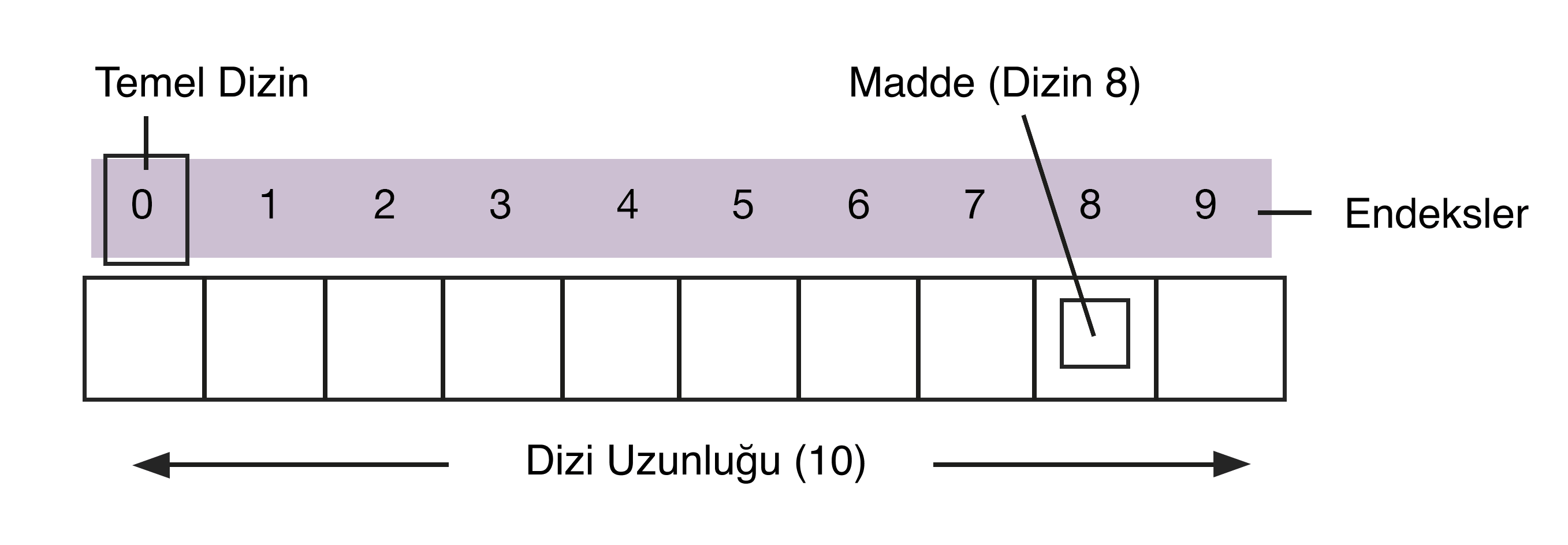
Bir dizi (masif) basit bir temel yapıdır. Yığınlar, sıralar ve listeler dizilerden türetilir. Dizideki bir veri birimine, konumunu gösteren bir sayı veya dizin atanır. Dizide bilgi içeren bir hücreyi bulmak için, dizinini temel öğeye eklemeniz gerekir. Temel eleman genellikle dizinin adı ile gösterilir.
Sayfaları 1'den 10'a kadar numaralandırılmış bir defter düşünün. Her sayfası bilgi içerebilir veya boş olabilir. Not defteri bir sayfalar dizisidir, sayfalar "defter" dizisinin öğeleridir. Programlı olarak, bir sayfadan dizinine bakarak bilgi alırsınız, yani "notebook +4" dördüncü sayfanın içeriğine atıfta bulunur.
Dizi, aynı türdeki öğeleri bitişik bellek konumlarında depolayan sabit bir yapıdır. Bir istisna vardır o da farklı türlerdeki verileri depolayabilen heterojen diziler. Diziler tek boyutlu ve çok boyutludur (diziler içinde diziler). Boyutları sabittir, bu nedenle zaten oluşturulmuş bir diziye yeni bir öğe ekleyemezsiniz. Eski diziyi kopyalamanız ve boyutunu artırarak yeni bir dizi oluşturmanız gerekir.


#2. Matris (Matrix)
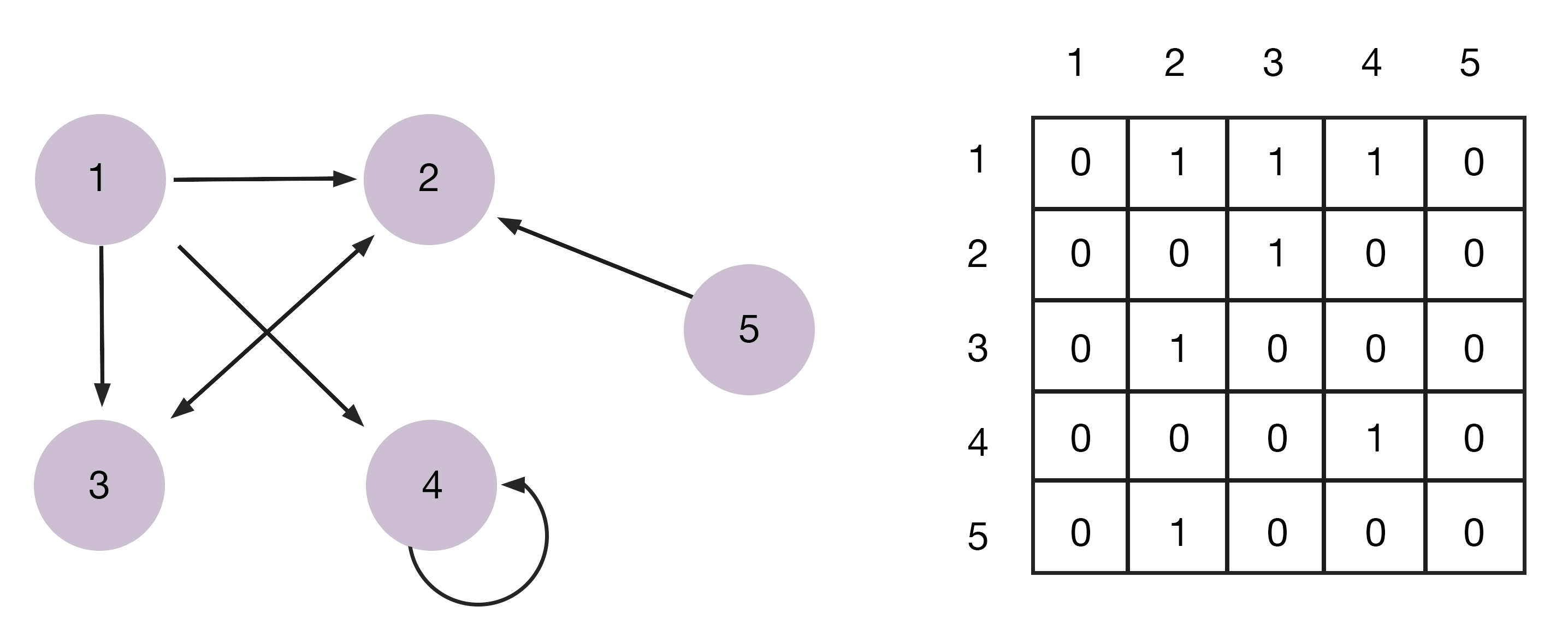
Matris, kesişme noktasında veri öğelerinin bulunduğu sütun ve satırların bir listesine benzeyen iki boyutlu bir dizidir. Bu, satır ve sütun sayısının boyutunu belirlediği dikdörtgen bir dizidir. Matematikte, cebir veya diferansiyel denklemlerin doğrusal denklemlerinin kompakt yazımı için kullanılırlar.
Matrisler olasılıkları tanımlamak için kullanılır. Örneğin, PageRank algoritmasını kullanarak Google aramasında sayfaları sıralamak için. Bilgisayar grafiklerinde - 3B modellerle çalışmak ve bunları iki boyutlu bir ekrana yansıtmak için kullanılır.
#3. Bağlantılı liste (Linked list)
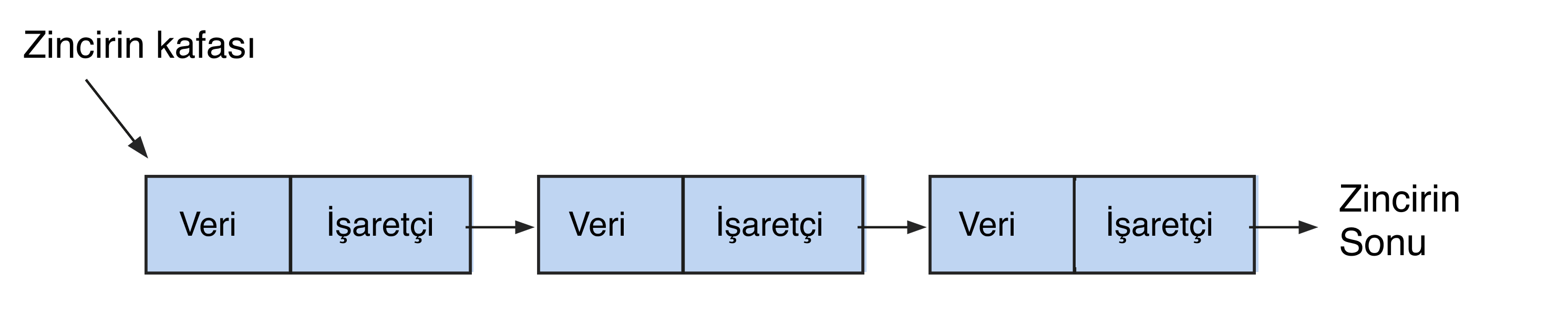
Listeler dizinlere benzer, ancak daha esnek bir yapıda farklılık gösterir. Her düğümün bir sonrakine bağlantı içerdiği düğüm zincirleri veya düğümler gibi görünürler. Bağlantılı bir listedeki öğelere, rastgele erişime sahip dizinlerin aksine sırayla erişilir. Listeler tek bağlantılı ve çift bağlantılıdır.
Bu yapının ilk elemanı baş olarak adlandırılır ve zincirin sonraki düğümleri kuyruk olarak adlandırılır. Kuyruk iki tür öğeden oluşur:
Bilgi (bilgi) ve bir sonraki düğümün göstergesi (sonraki). Zincirin sonu null olarak işaretlenir.
#4. Stek (Stack)
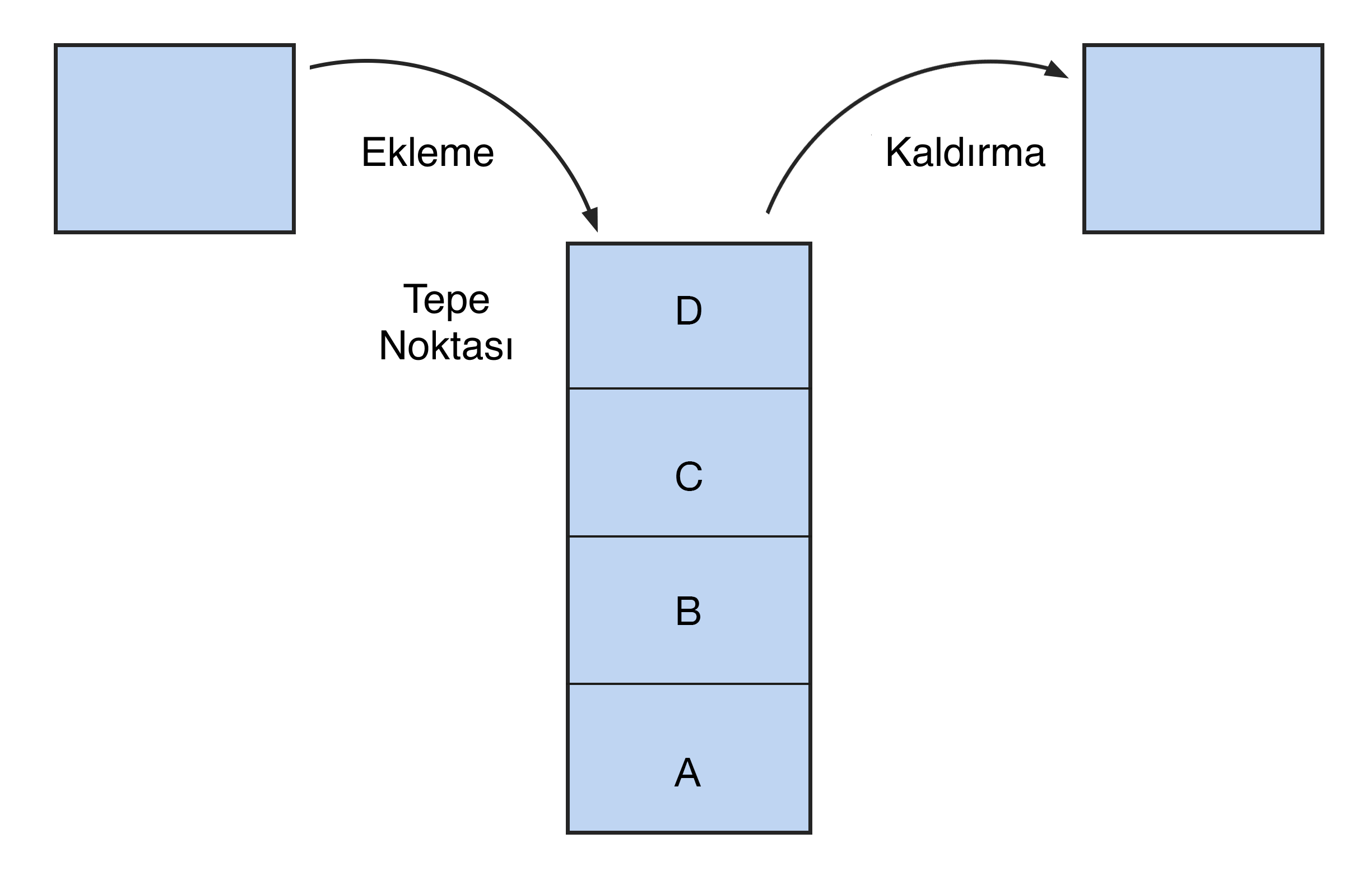
Bu sadece bir uçtan erişilebilen bloklarla: üstten veya alttan dikey bir sütundur. Bir kitap yığınında olduğu gibi, en alta gelmek için önce üstteki tüm kitapları çıkarmanız gerekir.
Yeni yığın öğeleri eskilerinin yerini alır. Böyle bir yapının çalışma prensibi LIFO'dur (son giren ilk çıkar).
Bu nedenle yığına şarjör de denir - ateşli silaha benzetilerek: en son yüklenen kartuş ateşlenir.
Bu veri yapısı, geri alma işlevinde uygulanır. Program, işin durumunu kaydeder, böylece son eylem iptal kuyruğundaki ilk eylem olur. Yığıtta yalnızca öğe ekleme (itme), çıkarma (pop), okuma (peek) üç işlem mümkündür.
Bir yığın, bağlantılı bir liste veya tek boyutlu bir dizi olarak uygulanabilir. İlk durumda, her eleman bir sonrakine bir bağlantı gönderir, ikinci durumda ise bir indekse göre sıralanır.
Benzer bir SD - deque (deque - çift uçlu sıra, "çift uçlu sıra") vardır. İki yönlü bir erişim yığınıdır.
#5. Sıra (Queue)
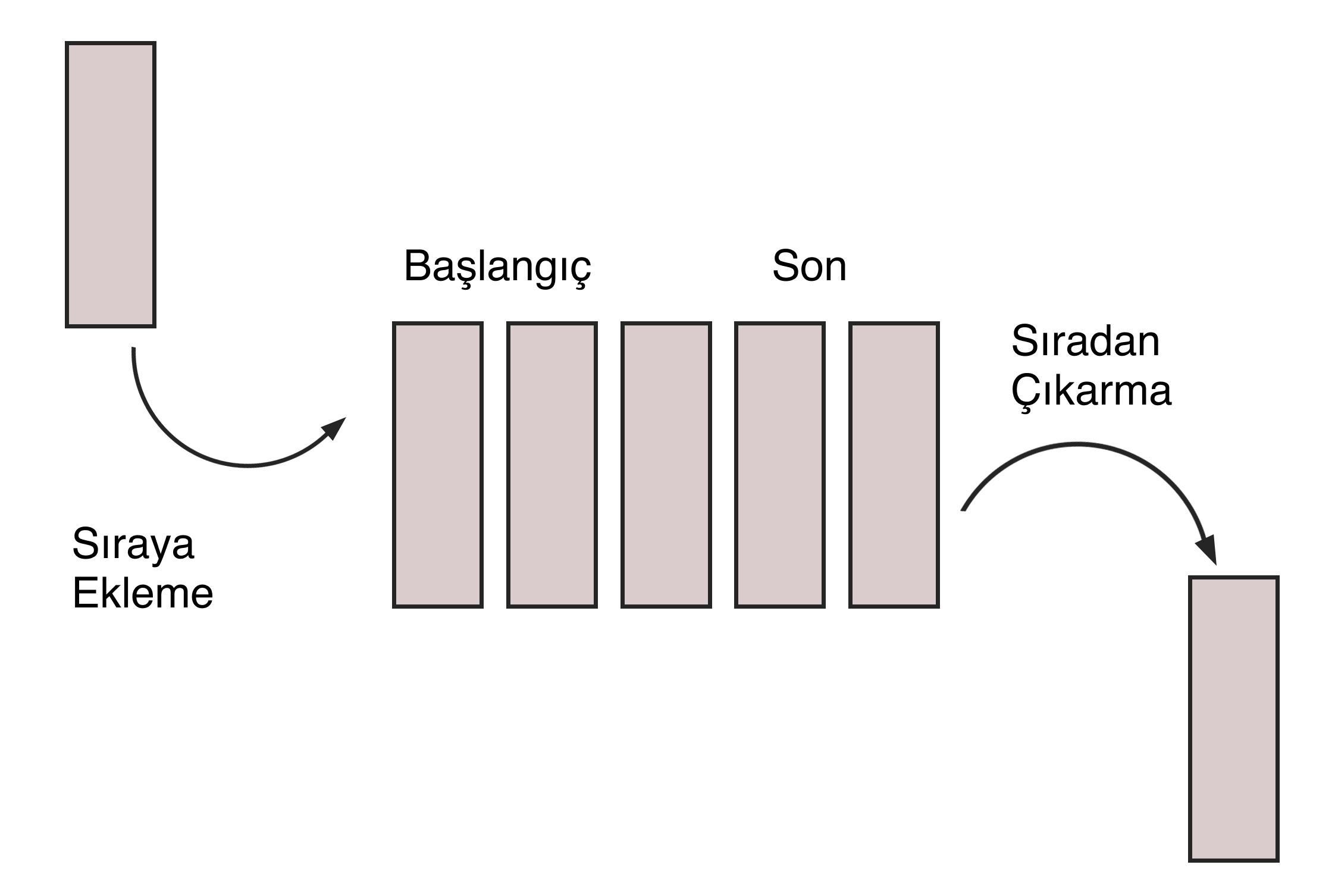
Bu SD tipi, yığınlara benzer, ancak çalışma prensibi FIFO olarak uygulanır (ilk giren - ilk çıkar, "ilk giren - ilk çıkar"). Bir süpermarkette olduğu gibi: alışverişi eve ilk götüren kişi, sıradaki ilk kişi olacaktır.
Kuyruklar, bir kaynağı birkaç tüketici (CPU işlemi, yönlendirici bant genişliği) arasında dağıtmak gerektiğinde kullanılır veya veriler asenkron olarak iletildiğinde, yani alım ve dönüş hızları farklıdır.
Bu SD'de iki işlem gerçekleştirilebilir:
Kuyruğun sonuna bir öğe eklemek (enqueue) ve ilk öğeyi çıkarmak (dequeue). Kuyruklar, yığınlara benzer şekilde bağlantılı listeler veya diziler biçimindedir.
#6. Ağaç (Tree)
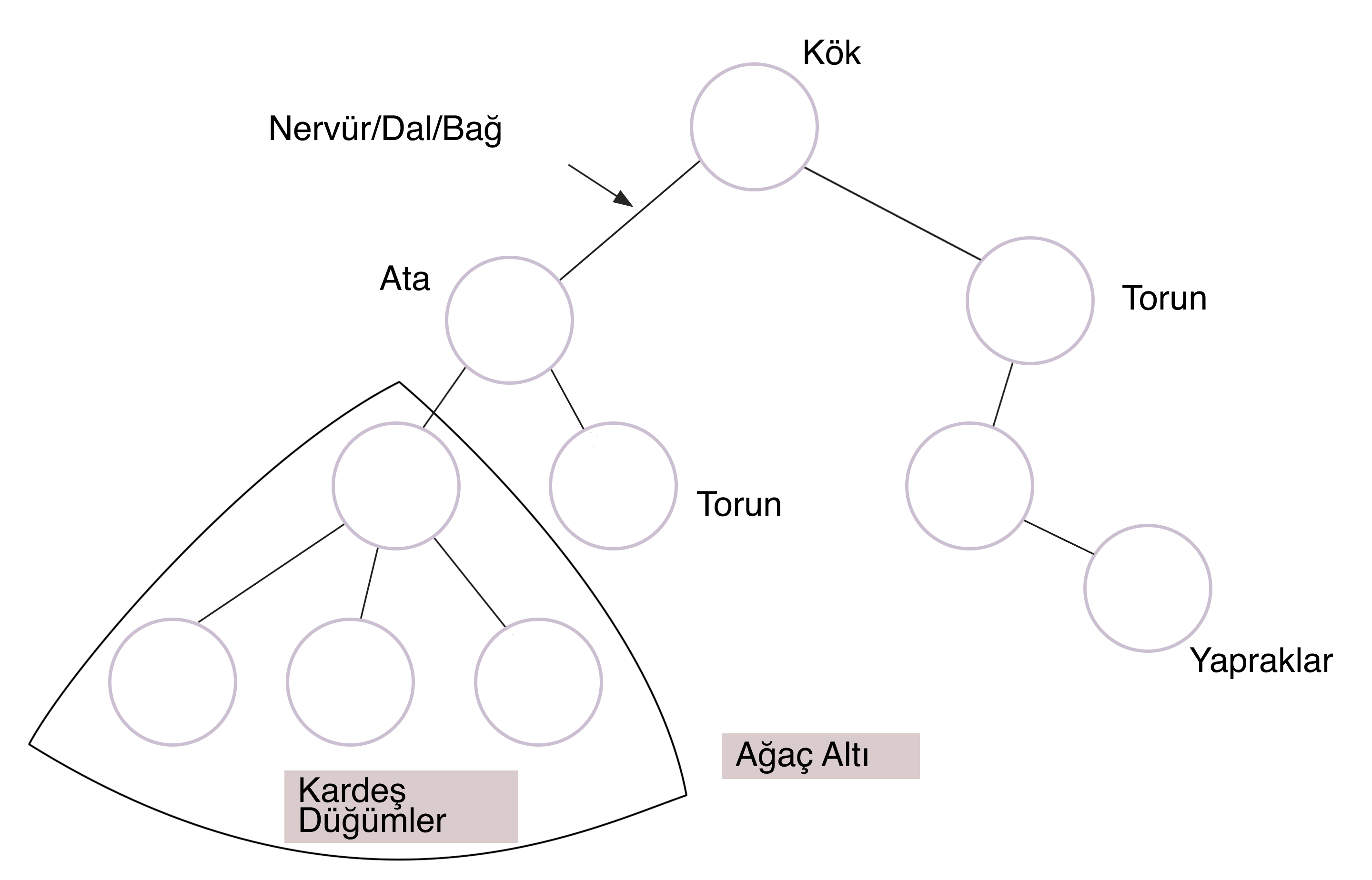
Ağaçlar, verilerin düğümlerle birbirine bağlandığı ve hatta hiyerarşik olarak düzenlendiği bir yapıdır. İkili arama ağacı, genişletilmiş, siyah ile kırmızı vb. birçok tür mevcuttur.
Gerçek bir ağaç gibi kökleri, dalları ve yaprakları vardır. Ataları olmayan bu SD'deki en yüksek düğüme kök düğüm denir. Diğer düğümler alt öğeler veya alt düğümler olarak adlandırılır. Aynı ebeveyne sahip alt düğümler, kardeş düğümlerdir ve yapraklar, torunları olmayan düğümlerdir.
Ağaçlar, örneğin video oyunları geliştirmek için kullanılır. Alanı bölmeyi ve nesneleri hızlı bir şekilde bulmayı mümkün kılarlar. Bu nedenle, oyunda dünyanın dört bir yanına bir harita ve yönlendirme oluşturmak için dört alt düğümü olan bir ağaç kullanılır.
Ancak ağaçların saklanması zordur ve çalışma hızları düşüktür.
#7. Yığın (Heap)
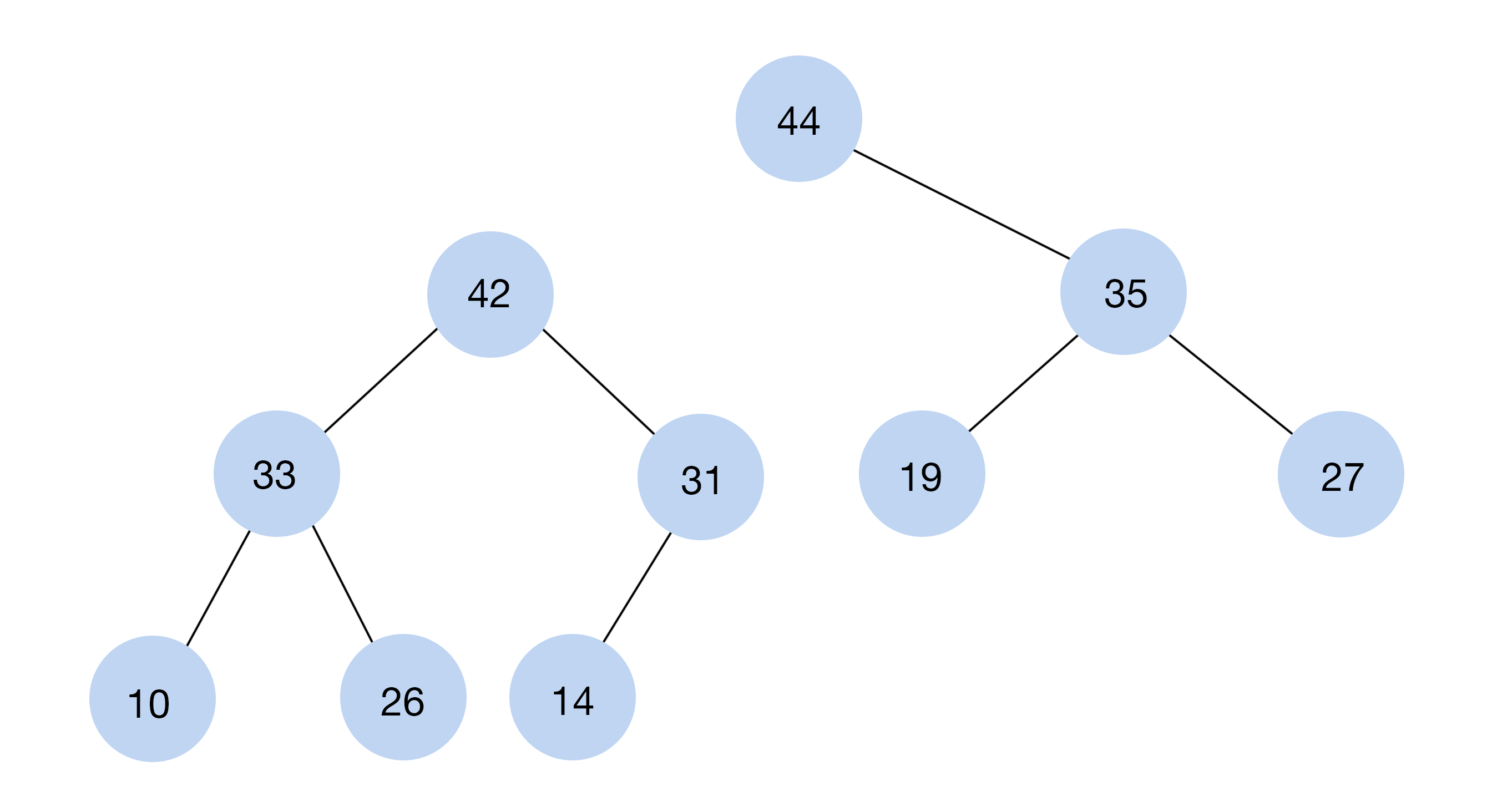
Yığınlar, ağaçlarla hemen hemen aynıdır: ayrıca kök düğümleri ve alt düğümleri vardır. Hiyerarşi sistemi farklıdır: iki tür yığın vardır:
Kök düğümlerin değerlerinin daha küçük olduğu ve değerlerin çocuklarınkinden daha büyük olduğu yığınlar. Bu SD'ler basit veya dinamik bir dizide saklanabilir, yani ağaçlardan çok daha az yer kaplarlar.
Öğelere yeni bir eleman eklemek için diğerlerine bakmanız gerekir. Öğeler, büyükten küçüğe doğru azalan sıra ile düzenlenir.
Yığınlar ise nesneleri sıralamak veya öncelik sıralarını uygulamak amacıyla kullanılır.
#8. Önek ağacı(Prefix tree)
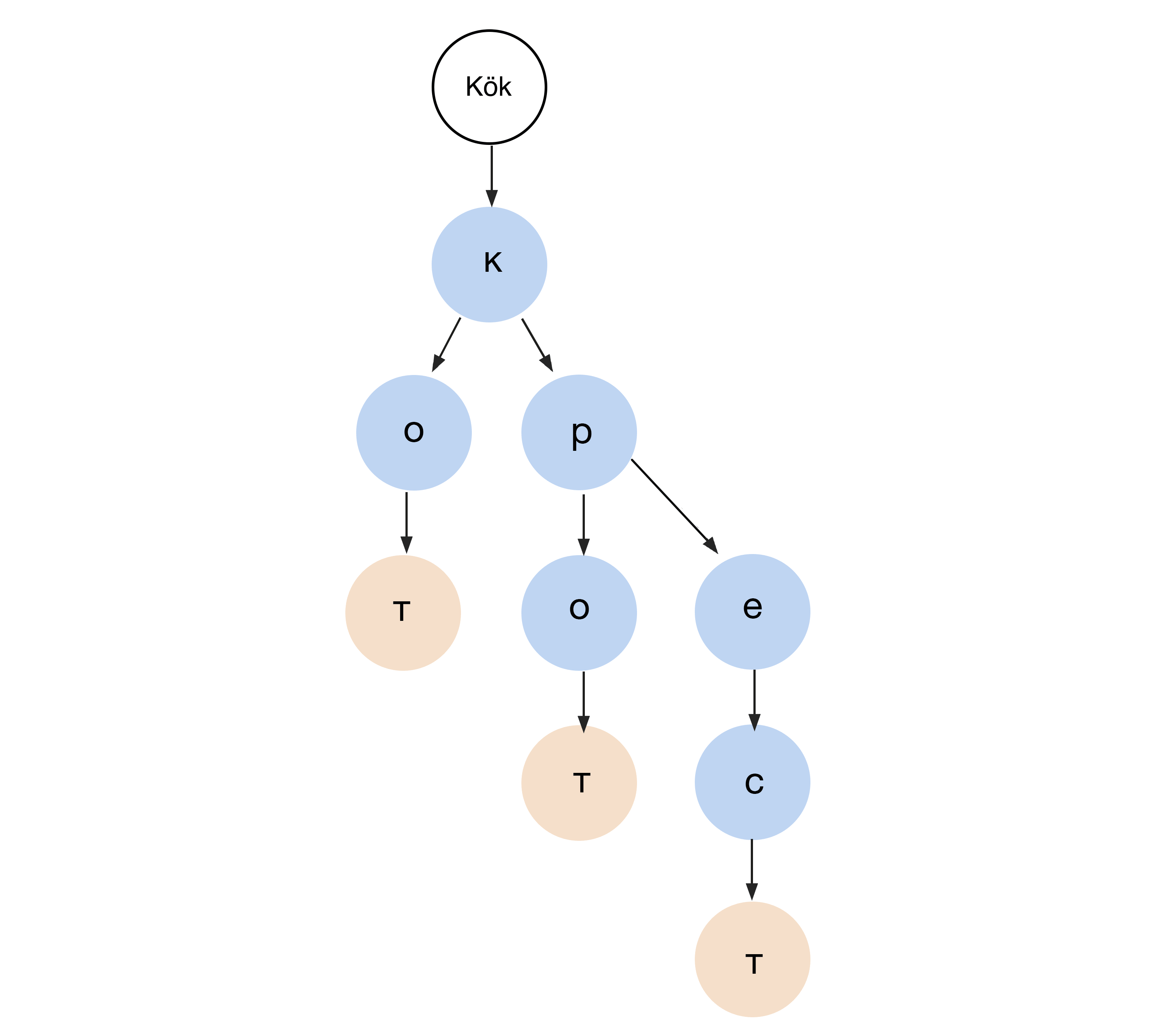
Otomatik tamamlamayı kullandığımızda önek ağacı adı verilen bir veri yapısı devreye giriyor. Bu, örneğin kelimeleri saklamak ve hızlıca aramak için kullanılan bir tür arama ağacıdır. Bu ağaçtaki düğümlere etiketler denir. Her etiket bir harf içerir, arama sırayla etiketlere göre ilerler. Harflerin sırası değişmeye başlayınca ağaç dallanır. Birkaç harf yazdığımızda size kelime öneren akıllı telefon hayal edin, işte buna benzer.
Önek ağacı, NLP'de ve doğal dillerin sözdizimsel analizi için kullanılır.
#9. Hash tablosu (Hash table)
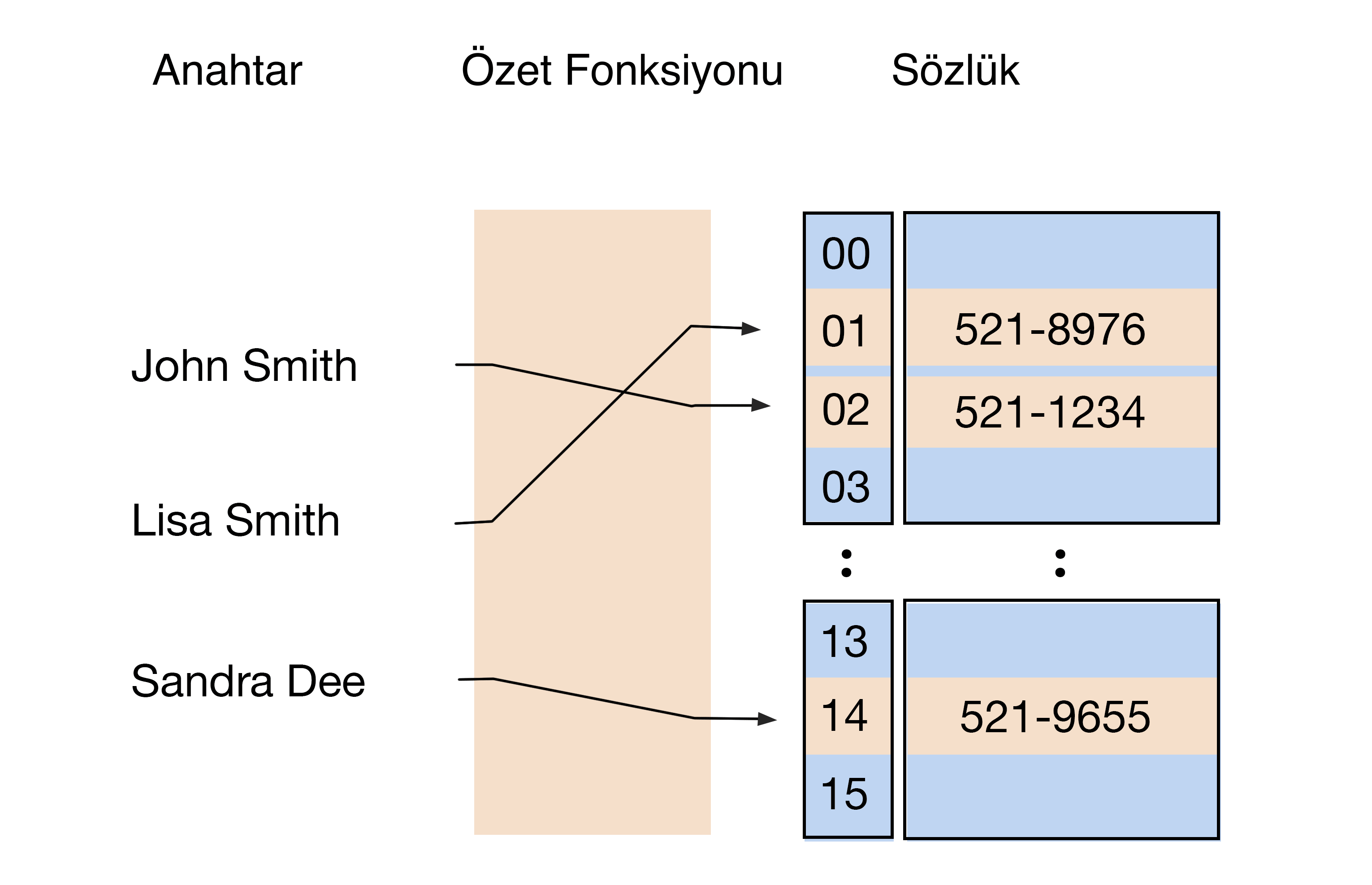
Hash tablosu, değerleri ve bunlarla ilişkili anahtarları depolayan bir SD'dir. Büyük bir kütüphane hayal edin. Orada bir kitap bulmak için genellikle bir dizine ihtiyacınız vardır. Karma algoritmayı kullanabilirsiniz, ardından işlev hemen kabinin numarasını ve içindeki kitabın konumunu verir. Bu, anahtarlar sayesinde olur. Dosyaya ve konumuna erişmek için bilgiler içerir. Hashing, kriptografide bilgileri şifrelemek için kullanılır.
Bir hash işlevi, uzun bir karakter dizisini kısa bir değere kısaltır. Bu, hash tablosundaki veri öğesinin anahtarı veya dizini olacaktır. Bir dizi veriye sözlük görevi görür de diyebiliriz.
Bir karma tablonun performansı, karma işlevine, tablonun boyutuna ve çarpışmaları işleme yöntemine bağlıdır.
Geeksfor Geeks, freeCodeCamp, Towards Data Science ve Alfred Aho, John Hopcroft ve Jeffrey Ullman'ın araştırmalarına dayanmaktadır.


