
SQL ile Nasıl Çalışılır: Yeni Başlayan Analistler İçin 17 Pratik İpucu
Etkili Teknikler ve Araçlar
Veri analizi alanında SQL (Structured Query Language – Yapılandırılmış Sorgu Dili), veri tabanlarıyla çalışmak için temel bir araçtır. Analistler, SQL sayesinde gerekli bilgiyi hızlıca alabilir ve verilerle kolayca etkileşim kurabilir.
SQL sezgisel bir sözdizimine sahiptir; bu da onu yeni başlayanlar için bile erişilebilir kılar. Aynı zamanda sunduğu güç ve işlevsellik, deneyimli analistlerin verilerle daha derin düzeyde çalışmasını sağlar. Temel SQL becerilerini edinmek kolay olsa da, gerçekten ustalaşmak zaman alabilir. Bu nedenle yeni başlayan analistlerin SQL'i daha etkili kullanmasına ve profesyonel seviyeye daha hızlı ulaşmasına yardımcı olacak 17 pratik ipucu hazırladık.
1. SELECT Komutunda Ustalaşın
Veri analistlerinin çalıştığı 5 farklı SQL komutu türü vardır:
DDL (Data Definition Language) – Veri tabanı yapısını (tablolar, şemalar, indeksler) oluşturmak ve değiştirmek için kullanılan Veri Tanımlama Dili.
DCL (Data Control Language) – Kullanıcılara veri tabanındaki verilere erişim izni vermek veya yasaklamak için kullanılan Veri Kontrol Dili.
TCL (Transaction Control Language) – İşlemlerin bütünlüğünü ve tutarlılığını sağlamak için kullanılan İşlem Kontrol Dili.
DML (Data Manipulation Language) – Mevcut tablolardaki bilgilerle çalışmak için kullanılan Veri İşleme Dili (ekleme, güncelleme, silme).
DQL (Data Query Language) – Veri tabanından veri seçimi için kullanılan Veri Sorgulama Dili. Biçimsel olarak DML'ye aittir, ancak ana SELECT komutunun kullanımının özgüllüğü nedeniyle genellikle ayrılır.
SELECT operatörü SQL'in temelini oluşturur. Çeşitli filtreler, sıralamalar ve birleştirmeler kullanarak bir veya birden fazla tablodan veri çeker. Bu, en sık çalışacağınız operatördür.
SELECT komutuna şu operatörler eklenebilir:
WHERE– verileri gerekli koşula göre filtreler;GROUP BY– verileri belirtilen özelliklere göre gruplandırır;HAVING– gruplamadan sonra uygulanan, belirlenmiş kriterlere göre verileri filtreler;JOIN– farklı birleştirme türlerini kullanarak birden fazla tablodan verileri birleştirir:INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN;LIMIT– veri seçimindeki satır sayısını sınırlar.
FROM Operatörü
FROM operatörü SELECT sorgularında zorunlu bir unsurdur ve verilerin hangi tablodan (veya tablolardan) alınacağını belirler. Sorgu için temel veri kaynağını belirtir. Birden fazla tablo kullanıldığında, FROM uygun koşullara göre farklı tablolardan verileri birleştirmek için JOIN ile birlikte çalışabilir.


Kullanım Örnekleri
#1. 'users' tablosundan 'name' ve 'age' sütunlarını seçme.
SELECT name, age
FROM users;
#2. * kullanarak 'users' tablosundan tüm sütunları seçme.
SELECT *
FROM users;
#3. WHERE kullanarak verileri filtreleme. Örneğin, yaşı 18'den büyük olan kullanıcıların verileriyle ilgileniyoruz.
SELECT name, age
FROM users
WHERE age > 18;
#4. AND, OR mantıksal operatörlerini kullanarak seçim koşullarını birleştirme. Önceki sorguyu, kullanıcıların Kiev'den olma koşuluyla tamamlayalım.
SELECT name, age
FROM users
WHERE age > 18 AND city = 'Kyiv';
Gördüğünüz gibi, SELECT operatörü VT ile çalışmak için temel bir araçtır. Bu nedenle, öğrenmeye ve pratikte kullanmaya yeterince zaman ayırmaya değer.
2. İç İçe Sorgular Kullanın
İç içe sorgu (alt sorgu) – başka bir SQL sorgusunun içindeki bir sorgudur ve karmaşık bir seçim veya analiz sürecini daha küçük adımlara böler. Bu şekilde, basit bir sorguyla elde edilmesi imkansız olacak verileri alabilirsiniz. VT ile çalışırken yeni olanaklar açmak ve seçim sürecine esneklik katmak için bu aracı kullanın. Potansiyellerini en üst düzeye çıkarmak ve karmaşık görevleri çözmek için farklı senaryolar için alt sorgular yazmayı deneyin.
Kullanım Örnekleri
- Ara sonuçları alma
Dizüstü bilgisayar satın alan müşterilerin adlarını çıkarmanız gerekiyor. İç içe sorgu önce dizüstü bilgisayar siparişi veren tüm kullanıcıları bulur (ara sonuç), ardından adlarını çıkarır.
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = 'dizüstü bilgisayar'
);
- Toplulaştırılmış verilere dayalı filtreleme
Şirkette ortalama maaşın üzerinde maaş alan çalışanları bulmanız gerekiyor.SELECTkomutuyla bunu yapmak imkansızdır. Bunun için süreç 2 aşamaya ayrılmalıdır: önce şirketteki ortalama maaşı hesaplamak ve ardından bu sonucu ilgili çalışanları aramak için kullanmak.
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
İç içe geçmiş sorgu sayısını sınırlayın. Aşırı karmaşık yapılar hata riskini artırır ve zamanla hangi verileri elde etmek istediğinizi hatırlamanız zorlaşır. Ayrıca, meslektaşlarınızın bu tür bir kodu anlaması da zor olacaktır. Olası hataları yakalamak için sorgu yürütme doğruluğunu ara aşamalarda da kontrol edin.
3. Ortak Tablo İfadelerini (CTE) Kullanın
Ortak Tablo İfadesi (CTE - Common Table Expression) – tek bir sorgu içinde birden çok kez kullanılabilen geçici bir sonuç veya sanal bir tablodur. İç içe sorgulara benzer şekilde, CTE karmaşık SQL sorguları için uygulanır. CTE'nin avantajı, kodu çoğaltmadan tekrar kullanılabilmesidir. CTE sayesinde, sorgularınızın yapısı net ve mantıksal bloklara ayrılmış olacaktır.
CTE'yi şu durumlarda uygulayın:
- ara hesaplamalar gerektiren karmaşık, çok düzeyli bir sorgu;
- aynı seçimin veya hesaplamanın tek bir sorgu içinde birden çok kez kullanılması;
- özyineleme gerektiğinde (özyinelemeli CTE) – özyinelemeli CTE'ler kendi tanımlarına atıfta bulunur, bu da hiyerarşik veya ağaç benzeri veri yapılarıyla çalışmaya olanak tanır.
CTE, WITH operatörü ile tanımlanır ve daha sonra SELECT, INSERT, UPDATE, DELETE veya MERGE komutlarında buna atıfta bulunulabilir.
CTE Kullanım Örneği
'employees' tablomuzun aşağıdaki sütunlara sahip olduğunu varsayalım:
- id – çalışanın benzersiz kimliği;
- name – çalışanın adı;
- department – departman adı;
- salary – çalışanın maaşı.
Verilen SQL sorgusu örneğinde, CTE 'employees' tablosundaki her departman için ortalama maaşı hesaplar. Kayıtları 'department' sütununa göre gruplandırır ve hesaplama sonucunu ve departman adını 'DepartmentAverageSalary' sanal tablosunda saklar.
Ana sorgu, ortalama maaşın 5000'den yüksek olduğu departmanları seçmek için CTE'yi kullanır, bu departmanın adını ve ortalama maaşını çıkarır.
//CTE
WITH DepartmentAverageSalary AS
(
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
)
//Ana sorgu
SELECT department, avg_salary
FROM DepartmentAverageSalary
WHERE avg_salary > 5000;
4. Pencere Fonksiyonlarına Dikkat Edin
Pencere fonksiyonu (Window function) seçilen bir dizi satır (pencere) ile çalışır ve bu dizi için hesaplamaları ayrı bir sütunda gerçekleştirir. Bu "pencereler", tablonun farklı sütunlarında yer alabilir, ancak hesaplamalar için önceden gruplandırılmaları gerekmez. Verileri gruplayan (GROUP BY) toplu fonksiyonların aksine, pencere fonksiyonları her satır için ayrı ayrı değerleri hesaplar, böylece hem işlenmemiş hem de işlenmiş verilerin aynı anda kullanılmasına olanak tanır.
Pencere fonksiyonları en sık sıralama, kümülatif hesaplamalar, zaman serisi analizi, hareketli ortalama yöntemi ve satırlar arasındaki farkların hesaplanması için kullanılır. Büyük veri kümelerinin analizini basitleştirmek ve işinizin verimliliğini artırmak için bunları kullanın.
Pencere fonksiyonları örnekleri:
ROW_NUMBER()– pencere içindeki her satıra benzersiz bir numara atar;RANK()– pencere içindeki satırlara sıralar atar, aynı değere sahip satırlar için aynı sıra değerine izin verir;SUM(), AVG(), MIN(), MAX()– belirlenmiş bir satır penceresi üzerinde toplu hesaplamalar yapar;PARTITION BY– hesaplama için satırları gruplara (pencerelere) ayırır;ORDER BY– her pencere içindeki satırların sırasını belirler.

5. JSON ile Çalışın
JSON (JavaScript Object Notation) – SQL'de yapılandırılmamış verilerin depolanması, işlenmesi, manipülasyonu ve değişimi için uygun bir formattır. Günümüzde veriler farklı formatlarda birçok kaynaktan gelmektedir, bu nedenle JSON bunlarla çalışmak için vazgeçilmez bir araçtır.
JSON şunları sağlar:
- farklı yapılara sahip verileri, bütünlüklerini ve ilişkilerini koruyarak depolamak ve analiz etmek;
- farklı kaynaklardan (harici API'ler, NoSQL VT, loglar vb.) kolayca veri içe aktarmak;
- veri modelini yeni sorgulara uyarlamak.
6. PIVOT ve UNPIVOT Operatörlerini Öğrenin
PIVOT ve UNPIVOT operatörlerini kullanarak verilerin yapısını değiştirerek tabloları dönüştürün.
PIVOT
Satırları sütunlara dönüştürmek, verileri toplamak ve analize daha uygun bir formatta sunmak için gereklidir. Örneğin, aylara göre ürün satış verilerini içeren bir tablonuz var:
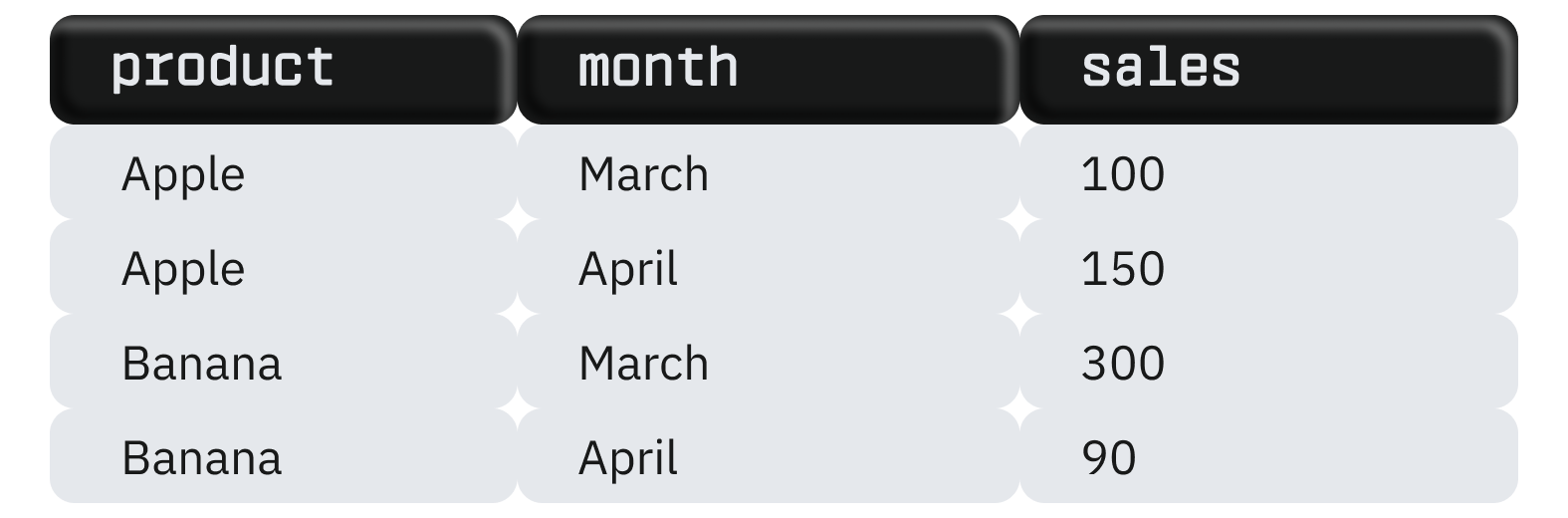
PIVOT kullanarak tabloyu, ayları sütunlara dönüştürerek değiştirebilirsiniz:
SELECT product, [March], [April]
FROM sales
PIVOT
(
SUM(sales)
FOR month IN ([March], [April])
)
AS PivotTable;
Sonuç:
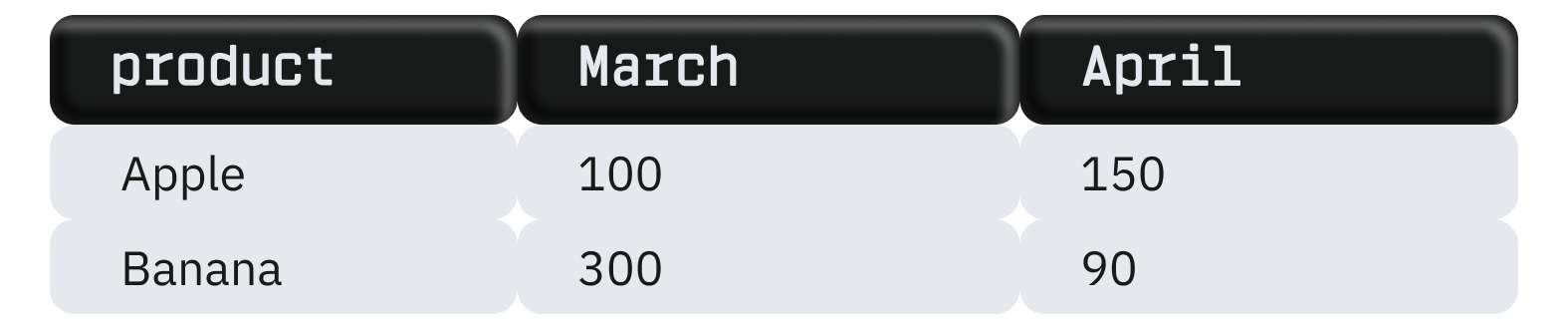
PIVOT operatörünün kullanımında belirli kısıtlamalar vardır:
- hangi değerlerin yeni sütunlar olacağını belirtmek gerekir;
- operatör, toplu fonksiyonlar (
SUM, AVG, COUNTvb.) uygulamadan satırları sütunlara dönüştüremez; - bazı veri türleri
PIVOT'ta kullanılamaz – örneğin, metin veri türleri ek dönüşümler veya işleme gerektirebilir; - tüm VT yönetim sistemleri desteklemez.
UNPIVOT
Daha esnek bir veri analizi gerektiğinde sütunları satırlara dönüştürmek için kullanılır. Örneğin, aylara göre ürün ciro miktarını içeren bir tablonuz var:
Ciro miktarının satır rolünde olacağı bir tabloya ihtiyacımız var. UNPIVOT operatörü yardıma gelir.
UNPIVOT operatörünün belirli kısıtlamaları vardır:
- birden fazla sütunu tek bir satıra çevirir – birden fazla bağımsız sütun grubunu aynı anda satırlara dönüştürmek için birden fazla sorgu kullanmanız gerekebilir;
- dönüştürülen sütunlar için tek bir veri türü gerektirir;
- tüm VT yönetim sistemleri desteklemez.
7. Sorguları İndekslerle Hızlandırın
VT'deki verilere hızlı erişim, sıralama ve gruplama için indeksleri kullanın. Bunlar, bir kitabın içindekiler tablosuna benzer şekilde çalışır: tüm tabloyu taramaya gerek kalmadan gerekli satırları hızlı bir şekilde bulmanızı sağlarlar. İndeksler sorgu performansını önemli ölçüde artırabilir, ancak ne zaman ve nasıl uygulanacağını bilmek önemlidir.
İndeks kullanımıyla ilgili birkaç ipucu:
- veri filtreleme için sıkça kullanılan satırlarda indeksler oluşturun;
- birincil anahtarlar
(PRIMARY KEY)için indeksleri uygulayın – bu, değerlerin tekrarlanmasını önleyecektir; - indeks sayısını sınırlayın – aşırı kullanımları ekleme
(INSERT), güncelleme(UPDATE)ve silme(DELETE)işlemlerini yavaşlatabilir, çünkü bu işlemlerin her biri indeksleri de güncellemelidir.
8. Sorguları Optimize Edin
Büyük hacimli verilerle çalışırken, bir veri analisti olarak, seçimin doğruluğuna ek olarak bilgi işleme hızı da önemlidir. Bu nedenle, işinizin verimliliğini artırmak için sorguları optimize etmenizi öneririz. Bu, EXPLAIN komutu ve SELECT *'nın akıllıca kullanılmasıyla yapılabilir.
SELECT * komutu, ihtiyacınız olmayan verileri çekebilir ve sorguları yavaşlatabilir. Sürekli tüm sütunları seçmek yerine, yalnızca ihtiyacınız olanları belirtin.
EXPLAIN komutu, VT yönetim sisteminin sorgunuzu tam olarak nasıl yürütmeyi planladığını görmenizi sağlar, indeks kullanımı, tablo birleştirme yöntemleri ve veri işleme sırası hakkında ayrıntılı bilgi sunar. EXPLAIN'i uygulayarak, sorgunun neden yavaş çalıştığını anlayabilir ve onu optimize etme yollarını bulabilirsiniz.
EXPLAIN komutunu kullanmak için, sorgunuzdan önce onu ekleyin. Sonuç, ayrıntılı bir yürütme planı içeren bir tablo olacaktır.
EXPLAIN SELECT name, age
FROM users
WHERE age > 30;
9. Etkili Birleştirme (JOIN) Komutlarını Kullanın
Birleştirme komutları olmadan büyük hacimli veri analizi neredeyse imkansızdır. En sık, birden fazla tablodan ilgili verileri elde etmek için gereklidirler. Etkisiz birleştirmeler kullanarak, sorguları önemli ölçüde yavaşlatma riskini alırsınız. Aynı zamanda, birleştirme yöntemlerini anlamak, sorgularınızın bilgililiğini artıracaktır.
SQL'de birkaç tür JOIN komutu vardır:
INNER JOIN. İki tablonun satırlarını birleştirir, sadece her iki tabloda da değerler arasında eşleşme olan kayıtları döndürür. Her iki tabloda da aynı değerlere sahip satırlar bulunursa, bunlar sonuca eklenecektir.LEFT JOIN / LEFT OUTER JOIN. Sol tablodan (sorguda belirtilen ilk tablo) tüm satırları ve sağ tablodan karşılık gelen satırları döndürür. Sağ tabloda eşleşme yoksa, sonuç bu tabloya ait sütunlar içinNULLiçerecektir.RIGHT JOIN / RIGHT OUTER JOIN. Sağ tablodan (sorguda belirtilen ikinci tablo) tüm satırları ve sol tablodan karşılık gelen satırları döndürür. Sol tabloda eşleşme yoksa, sonuç bu tabloya ait sütunlar içinNULLiçerecektir.FULL JOIN / FULL OUTER JOIN. Sol veya sağ tabloda eşleşme olan tüm satırları döndürür. Her iki tabloda da yoksa, sonuç her ikisinden de eksik değerler içinNULLiçerecektir.CROSS JOIN. İki tablonun Kartezyen çarpımını döndürür. Yani, ilk tablonun her satırı ikinci tablonun her satırıyla birleştirilir.SELF JOIN. Tablonun kendi kendisiyle birleştirildiği ayrı birJOINkomutu örneğidir. Hiyerarşik ilişkiler içeren tablolardaki verileri analiz etmek için kullanışlıdır (örneğin, çalışanlar ve yöneticileri).
INNER JOIN komutu, genellikle birleştirilen tablolardan yalnızca eşleşen satırları döndürdüğü için daha hızlı çalışır. Ancak, göreve bağlı olarak kullanılmalıdır; bu evrensel bir çözüm değildir.
Birleştirme komutlarına katılan sütunlara, özellikle yabancı anahtarlara indeksler atandığından emin olun.
10. Veri Ambarları ve Veri Tabanlarıyla Çalışmada Ustalaşın
Veri ambarları (Data Warehouses), veri tabanlarının (Databases) aksine, karmaşık ve zorlu hesaplamalar için daha uygundur, bilgiyi gerçek zamanlı olarak güncellemek zorunda değildir ve farklı yapılara sahip veriler içerebilir. Modern şirketlerde çalışırken, en sık bulut veri ambarlarıyla uğraşacaksınız. Ancak, SQL sorgularını hem yerel veri tabanlarına hem de bulut ambarlarına yapmayı öğrenmenizi öneririz.
Sorgu optimizasyon yaklaşımlarındaki farklılıkları ve veri işlemenin özelliklerini daha iyi anlayacaksınız. Yerel veri tabanları, belirli donanım ve yapıya göre optimizasyon gerektirir. Bir analist olarak, sınırlı depolama hacmi ve hesaplama kaynakları koşullarında çalışabilmeniz sizin için faydalı olacaktır.
Bulut ambarları esneklik, ölçeklenebilirlik ve herhangi bir yerden büyük hacimli verilere kolay erişim sunar. Ancak, bunlarla çalışmak için bulut mimarisinin özelliklerini, sorgu işleme maliyetini ve veri güvenliğini anlamak gerekir.
Örneğin, Google'ın bulut ambarındaki SQL sorgularıyla ilgili eğitim materyallerini kullanabilirsiniz.
11. Analiz İçin Verileri Hazırlayın
Etkili veri analizi, yalnızca kaliteli veri hazırlığı ile mümkündür. Verileri standartlaştırma ve gereksiz bilgilerden temizleme yeteneği, etkili SQL sorgularını anlamak kadar önemlidir. Listelenen operatörleri öğrenmeye dikkat edin ve bunları pratikte uygulamaya çalışın:
UPPERveLOWER– satır değerlerini sırasıyla büyük veya küçük harflerle yazar;REPLACE– belirtilen dize değerlerini başka bir dize değeriyle değiştirir (örneğin, 'sok.' yerine 'sokak' yazılabilir);SUBSTRING– komutta belirtilen metin parçasını döndürür;TRIM– satırın başındaki ve sonundaki boşlukları kaldırır;DATE_FORMAT– tarih ve saat için gerekli formatı belirlemenizi sağlar;CASE WHEN– verileri koşullara göre dönüştürür.
12. Örnek Veri Tabanlarını Kullanın
SQL bilgi seviyeniz ne olursa olsun, farklı veri tabanlarıyla denemeler yapmak her zaman kendi becerilerinizi güçlendirmenize yardımcı olacaktır. Başlangıç seviyesinde bir analistseniz, özellikle örnek veri kümelerine (Datasets) dikkat etmenizi öneririz. Bunlar genel, finansal-ekonomik, sağlık, E-ticaret, SMM ve jeo-uzamsal veriler içeren setlerdir. Her biri, çalışması ilginç ve faydalı olan farklı veri setleri içerir. Örneğin:
- Northwind Sample Database – küçük bir kurgusal şirketin VT'sini taklit ettiği için SQL öğrenimi için klasiktir;
- AdventureWorks Sample Database – Microsoft tarafından SQL Server'ın yeteneklerini göstermek için oluşturulmuştur. Yeni başlayanlar için mükemmel bir VT seçeneğidir;
- World Bank Economic Data – Dünya Bankası tarafından sağlanan, dünya ülkelerinden büyük bir finansal ve ekonomik veri setidir. Ekonomi analizi ve tahminler için faydalı olacaktır;
- CDC Datasets – Hastalık Kontrol ve Önleme Merkezleri (CDC) tarafından sağlanan ve hastalık takibi, epidemiyoloji ve halk sağlığı ile ilgili bilgiler içerir. Sağlık alanındaki trendleri analiz etmek ve izlemek için ilginç olabilir.
13. ChatGPT Kullanın
Sizi şaşırtmayacağımızı düşünüyoruz, ancak bu tavsiyeyi ihmal etmeyin. ChatGPT, SQL becerilerinizi öğrenme ve geliştirme konusunda gerçek bir yardımcı olabilir. Şunlar için kullanılabilir:
- SQL kodunu kontrol etme;
- hata mesajlarının şifresini çözme;
- kodun hangi sonucu vereceğini veya hangi eylemleri gerçekleştirdiğini açıklama;
- komutlar arasındaki farkları öğrenme ve durumunuzda hangisinin en iyi olduğuna karar verme;
- insan dilindeki sorguyu SQL koduna "çevirme".
ChatGPT'nin yetenekleri verilen örneklerle sınırlı değildir. Kendi deneyiminizle kolayca tamamlayabilir ve SQL becerilerinizi bugün güçlendirmeye başlayabilirsiniz. En önemlisi, ChatGPT'nin hata yapabileceğini ve ilk seferde doğru sonucu vermeyebileceğini unutmayın. Bilgiyi ek olarak kontrol edin, ona tekrar sorun, daha fazla bağlam sağlayın ve net sorular sorun.

14. Kodu Biçimlendirin
Bu tavsiye, kod yazan herkes için evrensel kabul edilebilir. SQL kodunun doğru biçimlendirilmesi, onu daha okunabilir, anlaşılır ve bakımı daha kolay hale getirmeye yardımcı olur. İşte uymanız gereken temel SQL kodu biçimlendirme ilkeleri:
SQL komutları ve operatörleri için büyük harf kullanın
Tüm kod düzenleyicileri komutları ve operatörleri farklı bir renkle işaretlese de, büyük harf kullanımı bunları diğer metinlerden ek olarak ayıracaktır:
❌ select, from, where, join, order by;
✅ SELECT, FROM, WHERE, JOIN, ORDER BY;
Kodu birden fazla satıra bölün
Bu, daha hızlı okunmasını ve özünün anlaşılmasını sağlar.
❌
SELECT name, age FROM users WHERE age > 18;
✅
SELECT name, age
FROM users
WHERE age > 18;
İç içe sorgular için girinti yapın
Önceki maddeye benzer şekilde, bu kodun okunabilirliğini artıracaktır.
❌
SELECT name
FROM buyers
WHERE id IN (SELECT user_id FROM orders WHERE product = 'dizüstü bilgisayar');
✅
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = 'dizüstü bilgisayar'
);
Operatörleri hizalayın
Karmaşık aritmetik veya mantıksal sorgular için, kodda girintiler ve hizalama kullanın ve operatörleri yeni satırlara taşıyın.
❌
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
✅
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
Yorum ekleyin
Karmaşık kod bloklarını veya amacını açıklamak için yorumları kullanın. Bu, kodu daha sonra açarsanız size ve meslektaşlarınızın sorguları anlamasına yardımcı olacaktır.
Kod düzenleyicisine bağlı olarak, yorumlar farklı sembollerle işaretlenebilir. Örneğin --, // veya /* */ (çok satırlı yorumlar için).
-- ortalama maaşın üzerinde maaş alan çalışanları buluyoruz
// ortalama maaşın üzerinde maaş alan çalışanları buluyoruz
/*ortalama maaşın
üzerinde maaş alan çalışanları buluyoruz */
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
15. En Önemlisi – Pratik
Yeni başlayanların iş bulması her zaman zordur, çünkü çoğu işveren pratik becerilerle ilgilenir. Peki, işte değilse, bunları nereden almalı? SQL Zoo gibi özel simülatörleri kullanabilirsiniz. Genellikle bu tür kaynaklar, sorgu oluşturma ve verilerle çalışma becerilerini geliştirmek için çeşitli SQL görevleri içerir.
16. Veri Görselleştirme
SQL, sorgu yapmanıza ve karşılığında gerekli verileri almanıza olanak tanır. Önceki tüm ipuçları, bilgiyle çalışmaya odaklanmıştı: hazırlama, alma, filtreleme, gruplama vb. Ancak bir veri analisti, yalnızca SQL kullanarak gerekli verileri almaya değil, aynı zamanda bunları görselleştirmeye de odaklanmalıdır.
SQL'de veri görselleştirme, büyük hacimli verileri anlamak ve kararlar almak için hayati öneme sahiptir. Bu nedenle, görselleştirme araçlarını öğrenmeye dikkat etmenizi ve iş ihtiyaçlarınızı karşılayan birini seçmenizi öneririz.
Örneğin, bunlar şunlar olabilir:
- Toucan – herhangi bir VT'ye hızlıca entegre edilebilen bir araçtır. Basit bir arayüze sahiptir ve yeni başlayanlar için uygundur.
- Looker Studio – Google Cloud'un bir parçasıdır. SQL sorguları oluşturmak ve veri modellemesi yapmak için kendi LookML diline sahiptir. Görselleştirme için geniş olanaklar sunar.
17. Kullanışlı Bir Kod Düzenleyici Seçin
Pek çok SQL kodu düzenleyicisi vardır ve her birinin kendine özgü avantajları ve özellikleri bulunur. Amaçları, veri analistlerinin SQL sorgularını yürütmelerine ve optimize etmelerine yardımcı olmaktır. SQL düzenleyicileri, veri tabanlarıyla çalışmayı basitleştirir, kod yazma, SQL sorgularını kontrol etme ve yürütme için rahat bir ortam sağlar. Ayrıca şunları yapabilirler:
- kodun okunabilirliğini artırmak için sözdizimini vurgulamak;
- kod yazmayı kolaylaştırmak için SQL fonksiyonlarını önermek;
- kodda sözdizimi hatalarını kontrol etmek;
- sorgu sonuçlarını görselleştirmek.
Kod düzenleyici örnekleri:
- MySQL Workbench – MySQL sunucularını ve veri tabanlarını yönetmek için MySQL'in resmi düzenleyicisidir.
- DBeaver – birçok veri tabanı türüyle çalışmak için evrensel, ücretsiz bir düzenleyicidir;
- Visual Studio Code (VS Code) – Microsoft tarafından Windows, Linux ve macOS için oluşturulmuştur. Hafif bir kod düzenleyicisi olarak kabul edilir. SQL veya veri tabanlarıyla çalışmak için bağımsız, özel bir araç değildir. Ancak uzantılar aracılığıyla VS Code, SQL, Python, R ve veri analizinde sıklıkla kullanılan diğer araçlar dahil olmak üzere hemen hemen her dili destekleyebilir.
Pek çok kod düzenleyicisi vardır. Hepsi yaklaşık olarak aynı işlevselliğe sahiptir, ancak farklı veri tabanlarıyla çalışmayı desteklerler. Çalışmak için bir düzenleyici seçerken buna dikkat edin.
Umarız ipuçlarımız, büyük veri analizi dünyasında kaybolmamanıza ve SQL yardımıyla ustaca ustalaşmanıza yardımcı olur.


